本文摘自网事全知道,侵删。

2020年8月PyCaret2.1 更新版本正式发布。
Py Caret是一个开源的、低代码率的Python机器学习库,它可以使机器学习工作流程自动化,同时,它也是一个端到端的机器学习和模型管理工具,可以缩短机器学习实验周期,将生产力提高10倍。
与其他开源机器学习库相比,Py Caret是低代码库的一个很好的选择,只需利用几个单词,便可以用它来替换数百行代码,从而使得实验快速高效。
如果以前没有听到或使用过PyCaret,请参阅先前发布的指南,以便快速入门。
安装PyCaret
安装Py Caret非常容易,只需要几分钟的时间。建议使用虚拟环境来避免与其他库的潜在冲突。请参阅下面的示例代码,以创建Conda环境并在该Conda环境中安装pycaret:
#创建conda环境
conda create --name yourenvname python=3.6
#激活环境
conda activate yourenvname
#安装pycaret
pip install pycaret
#创建与conda环境链接的notebook内核
python -m ipykernel install --user --name yourenvname --display-name "display-name"
如果已经安装好了PyCaret,还可以使用pip对它更新:
pip install --upgrade pycaret
PyCaret 2.1特征概述

照片来源: Paweł Czerwiński
GPU上的超参数调优
PyCare t2.0支持某些算法(如:XGBoost、LightGbm和Catboost)的GPU训练。PyCare2.1中添加了新的内容,可以实现在GPU上对这些模型的超参数调优。
#使用GPU 训练xgboost
xgboost = create_model('xgboost', tree_method = 'gpu_hist')
#xgboost 调优
tuned_xgboost = tune_model(xgboost)
由于tune_model函数自动从create_model函数创建的xgboost实例中继承了tree_method,因此在tune_model函数内部不需要其他参数。请参看下图:
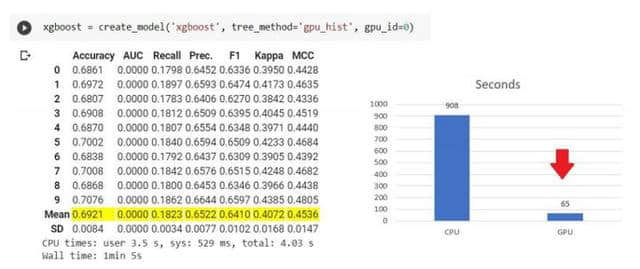
在GPU上进行XGBoost训练(使用googlecolab)
模型部署
自从PyCaret于2020年4月发布第一个版本以来,只需使用Notebook 中的deploy_model ,就可以在AWS上部署经过训练的模型。在最近的版本中,添加了支持在GCP和Microsoft Azure上部署的功能。
Microsoft Azure
若要在Microsoft Azure上部署模型,必须设置连接字符串的环境变量。可以从Azure中存储帐户的“访问密钥”获取连接字符串。
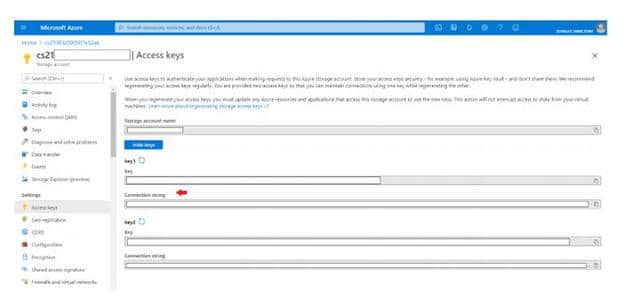
https:/http://portal.azure.com — 从账户中获取链接字符串
复制连接字符串后,可以将其设置为环境变量,参见以下示例:
导入os
os.environ['AZURE_STORAGE_CONNECTION_STRING'] = 'your-conn-string'
从 pycaret.classification 中导入 deploy_model
deploy_model(model = model, model_name = 'model-name', platform = 'azure', authentication = {'container' : 'container-name'})
成了,就是这样。只需一行代码,整个机器学习管道都已在Microsoft Azure容器中了,随后可以使用 加载模型 函数访问它。
导入os
os.environ['AZURE_STORAGE_CONNECTION_STRING'] = 'your-conn-string'
从pycaret.classification 中导入 load_model
loaded_model = load_model(model_name = 'model-name', platform = 'azure', authentication = {'container' : 'container-name'})
从pycaret.classification 中导入predict_model
predictions = predict_model(loaded_model, data = new-dataframe)
谷歌云平台
要在Google云平台(GCP)上部署模型,必须首先使用命令行或GCP控制台创建一个项目。创建项目后,应创建服务帐户并将服务帐户密钥下载为JSON文件,然后使用该文件设置环境变量。
导入os
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'c:/path-to-json- file.json'
从pycaret.classification 导入deploy_model
deploy_model(model = model, model_name = 'model-name', platform = 'gcp', authentication = {'project' : 'project-name', 'bucket' : 'bucket-name'})
加载模型之后,可以使用 load_model 函数从GCP bucket中访问模型。
导入os
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'c:/path-to-json- file.json'
从pycaret.classification 导入load_model
loaded_model = load_model(model_name = 'model-name', platform = 'gcp', authentication ='project-name', 'bucket' : 'bucket-name'})
从pycaret.classification导入predict_model
predictions = predict_model(loaded_model, data = new-dataframe)
MLFlow部署
除了使用PyCaret的本机部署功能之外,还可以使用MLFlow部署功能。利用setup函数的log_experiment登录参数
#初始化设置
exp1 = setup(data, target = 'target-name', log_experiment = True, experiment_name = 'exp-name')
#创建xgboost模型
xgboost = create_model('xgboost')
#其余的脚本
#在local host:5000上启动mlflow服务器
!mlflow ui
在浏览器上打开https://localhost:5000
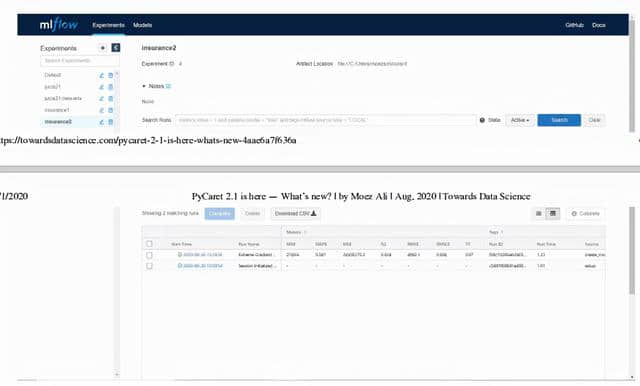
https://localhost:5000上的MLFlow UI
点击“Start Time”查看细节,在“Run Name” 的左边显示的是经过训练的模型的所有超参数和评分指标,向下滚动,所有的代码也会显示出来(见下文)。

MLFLow代码
经过训练的模型和所有元数据文件存储在“/model”目录下。MLFlow遵循一种标准格式来打包机器学习模型,以便在各种下游工具中使用,例如,通过REST API 或Apache Spark上的批处理推理进行实时服务。如果需要在本地为这个模型提供服务,可以利用MLFlow命令行来实现。
mlflow models serve -m local-path-to-model
然后,可以利用CURL将请求发送给模型以获得预测。
curl http://127.0.0.1:5000/invocations -H 'Content-Type: application/json' -d '{
"columns": ["age", "sex", "bmi", "children", "smoker", "region"],
"data": [[19, "female", 27.9, 0, "yes", "southwest"]]
(注:MLFlow的这一功能尚不支持Windows操作系统)。
MLFlow还提供与AWS Sagemaker和Azure机器学习服务的集成,可以在与SageMaker兼容的环境下,在Docker容器中本地训练模型,也可以在SageMaker上远程训练模型。远程部署到SageMaker,需要设置环境和AWS用户帐户。
使用MLflow CLI的示例工作流
mlflow sagemaker build-and-push-container mlflow sagemaker run-local -m mlflow sagemaker deploy
MLFlow模型注册表
MLflow模型注册表组件是一个集模型存储、API集和UI为一体的组件,用于实现MLflow模型整个生命周期内的协同管理。它提供模型演习(MLflow实验并运行生成的模型)、模型版本控制、阶段转换(例如从例程到量产)和注释等服务。
如果需要运行MLflow服务器,则必须 使用数据库支持的后端存储才能访问模型注册表。但是,如果正在使用 数据包 或任何托管数据包服务,如 Azure Databricks,则无需担心设置的内容。
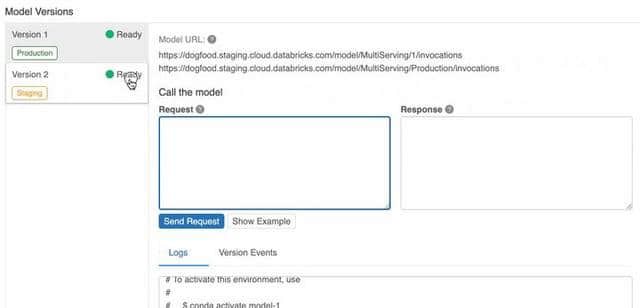
高分辨率绘图
这一功能并不是开创性的,但对于使用PyCaret进行研究和发表文章的人来说,这确实是一个非常有用的补充。plot_ model带有一个名为“scale”的附加参数,通过它可以控制分辨率并为出版物生成高质量的绘图。
#创建线性回归模型
lr = create_model('lr')
#高分辨率绘图
plot_model(lr, scale = 5) # default is 1
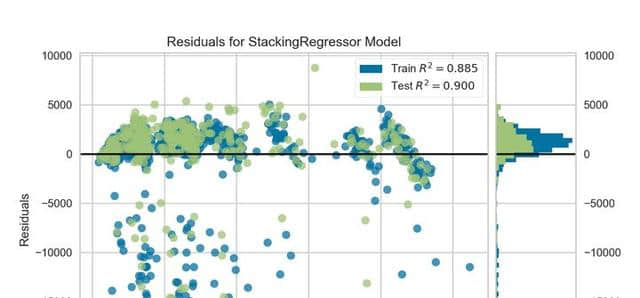
PyCaret的高分辨率绘图
用户定义的损失函数
这是自第一个版本发布以来请求最多的特性之一,它允许使用自定义/用户定义函数调整模型的超参数,从而给数据科学家带来了极大的灵活性。现在可以使用 tune_model函数的custom_scorer 参数来自定义损失函数。
#定义损失函数
de#使用sklearn创建记分器
from sklearn.metrics import make_scorer
my_own_scorer = make_scorer(my_function, needs_proba=True)
#训练catboost模型
catboost = create_model('catboost')
#使用自定义记分器调整catboost
tuned_catboost=tune_model(catboost,custom_scorer=my_own_scorer)
特征选择
特征选择是机器学习的基本步骤,在一大堆特征中,只想选择相关的特征而放弃其他特征,这样可以去除会引入不必要噪声的无用特征,从而使问题得以简化。
在PyCaret2.1中,利用Python实现了Boruta算法(最初是用R实现的)。Boruta是一个非常聪明的算法,可以追溯到2010年,旨在自动对数据集执行特征选择。在setup 函数中运行feature_selection_method方法
exp1 = setup(data, target = 'target-var', feature_selection = True, feature_selection_method = 'boruta')
其他变更
compare_models函数中的blacklist 和whitelist 参数已变更为exclude 和 include
在 compare_models函数中设置训练时间的上限,添加了新参数budget_time
PyCaret 可以与Pandas 的数据类型兼容,它们在内部被转换为object,并与处理 object 或 bool 一样。
在数值处理部分,在setup 函数 的numeric_imputation参数中添加了zero 方法当method设置为 zero 时,将其替换为常数0。
为了方便阅读,predict_model 函数返回Label 列的原始值而不是编码值。
要了解pycaret2.1中所有更新的更多信息,请参阅发行说明。
相关阅读 >>
吉利汽车金融有限公司电话大全已更新2023(实时/更新中)中国移动挂牌成立中移智库,打造数字经济领域高端智库
苹果中国官网开启夏季大促,iphone 13系列全系优惠600元
canalys:2021年q3中国云基础设施服务支出达72亿美元
永劫无间:新英雄岳山太无解?虎牙法神被打自闭:“国家队”解散
更多相关阅读请进入《新闻资讯》频道 >>




