本文摘自雷锋网,原文链接:https://www.leiphone.com/category/academic/pjrSC2DT2MrRCi8v.html,侵删。

作为深度学习的大牛,Bengio 对系统 1 和系统 2 是真爱,以往的演讲主题基本离不开这两个概念,今年终于换题目了!那么,Bengio 新推的人工智能算法 GFlowNets 究竟有何特别之处?
2021 年 11 月 1 日至 11 月 2 日,三星在线上举行为期两天的 2021三星人工智能论坛(Samsung AI Forum 2021)。今年是论坛举办的第 5 年,主题为「未来的人工智能研究」,聚集了世界知名的人工智能领域学者和行业专家,交流思想、见解和研究成果,探讨人工智能未来的方向。
三星人工智能论坛第一天的主题演讲由蒙特利尔大学的 Yoshua Bengio 教授发表,Bengio 也是三星人工智能论坛的联合主席,是三星人工智能教授。在题为 GFlowNets for Scientific Discovery 的主题演讲中,Bengio 提出了一种名为 GFlowNets 的新算法,不局限于在单一性质指标下寻找某一个最佳匹配的分子,而是将目标放大,基于生成模型,学习到满足性质指标的足够好的多种分子候选,更一般地说,是满足此性质指标的分子结构的概率分布函数。
也就是说,结合生成模型来学习科学实验数据,GFlowNets 使得获取的可行实验设置不局限于在单一的量化目标下的单一候选,而可以生成多样化的实验候选分布,不仅可以提高对科学实验和测试数据的预测精度,更重要的是提高实验设置的多样性。
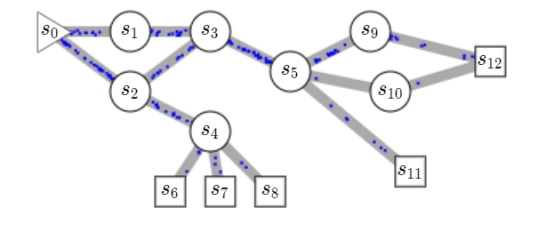
实现这一点的关键在于“流”的建模,也就是从一个侯选开始,逐步采样其它候选,同时在采样过程中,要通过奖励函数设置保证流入和流出是平衡的,也就是流守恒。具体而言,如上图所示,就是从初始候选 s_0 到达终端候选 s_12 的奖励,与从第二候选 s_1 到达终端候选 s_12 的奖励,是相等的。
Bengio 表示,这种采样方式与 MCMC 有相似之处,但是相比之下少了很多随机性,从而计算量大幅降低。
此外,这种基于历史候选逐步生成新候选的采样方式,与人类在进行科学探索时,参考前人成果的方式有相似之处,也就是阅读和学习——构建世界模型——提出问题(实验候选)——向现实世界提问和查询——获取反馈——修改世界模型——提出新问题。对于这种不同于传统的、静态的监督学习的范式,Bengio 将其称为生成式主动学习,它让我们不再局限于寻找“一个分子”,而可以寻找“一类分子”。
相关论文已经发表在arXiv上,代码也已经开源。

Yoshua Bengio:蒙特利尔大学的全职教授,也是魁北克人工智能研究所 Mila 的创始人和科学主任,全球公认的人工智能领域的领先专家之一。因在深度学习方面的开创性工作而闻名,与 Geoffrey Hinton 和 Yann LeCun 一起获得了 2018年AM 图灵奖。2019年,Yoshua Bengio 获得了著名的基拉姆奖,并于 2021 年成为世界上被引用次数第二多的计算机科学家。
Yoshua Bengio 教授作为高级研究员共同指导 CIFAR 机器和大脑学习计划,并担任 IVADO 的科学总监。他是伦敦和加拿大皇家学会的会员,也是加拿大勋章的官员。
以下是报告全文,AI科技评论进行了不改变原意的整理。
这篇论文是关于从一系列动作中学习生成对象(如分子图)的随机策略的问题,这样生成对象的概率与该对象的给定正奖励成正比。虽然标准回报最大化趋向于收敛到单个回报最大化序列,但在某些情况下,我们希望对一组不同的高回报解决方案进行采样。
例如,在黑盒函数优化中,当可能有几轮时,每轮都有大量查询,其中批次应该是多样化的,例如,在新分子的设计中。也可以将其视为将能量函数近似转换为生成分布的问题。虽然 MCMC 方法可以实现这点,但它们很昂贵并且通常只执行局部探索。
相反,训练生成策略可以分摊训练期间的搜索成本并快速生成。使用来自时间差异学习的见解,我们提出了 GFlowNets ,基于将生成过程视为流网络的观点,使得处理不同轨迹可以产生相同最终状态的棘手情况成为可能,例如,有很多方法可以顺序地添加原子以生成一些分子图。我们将轨迹集转换为流,并将流一致性方程转换为学习目标,类似于将 Bellman 方程转换为时间差分方法。
我们证明了提议目标的任何全局最小值都会产生一个策略,该策略从所需的分布中采样,并证明 GFlowNets 在奖励函数有多种模式的简单域和分子合成任务上的改进性能和多样性。
强化学习 (RL) 中预期回报 R 的最大化通常是通过将策略 π 的所有概率质量放在最高回报的动作序列上来实现的。在本文中,我们研究了这样一种场景,我们的目标不是生成单个最高奖励的动作序列,而是采样轨迹分布,其概率与给定的正回报或奖励函数成正比。
这在探索很重要的任务中很有用,即我们想从返回函数的前导模式中采样。这相当于将能量函数转化为相应的生成模型的问题,其中要生成的对象是通过一系列动作获得的。通过改变能量函数的温度(即乘法缩放)或获取返回的幂,可以控制发生器的选择性,即仅在低温下从最高模式附近产生或探索更多更高的温度。
这种设置的一个激励应用是迭代黑盒优化,其中学习者可以访问一个 oracle,该 oracle 可以为每一轮的大量候选者计算奖励,例如,在药物发现应用中。当 oracle 本身不确定时,生成的候选者的多样性尤其重要,比如,它可能由细胞检测组成,这是临床试验的廉价代理,或者它可能由对接模拟的结果组成(估计候选者小分子与目标蛋白结合),这是更准确但更昂贵的下游评估(如细胞检测或小鼠体内检测)的代表。
当调用 oracle 很昂贵时(例如涉及生物实验),Angermueller 等人(2020年)已证明在此类探索环境中应用机器学习的标准方法是获取已经从 oracle 收集的数据(例如一组( x, y) 对,其中 x 是候选解,y 是来自 oracle 的 x 的标量评估)并训练一个监督代理 f(被视为模拟器),它从 x 预测 y。函数 f 或 f 的变体包含其值的不确定性,如贝叶斯优化(Srinivas 等人,2010 年;Negoescu 等人,2011 年),然后可以用作奖励函数 R 来训练生成模型或一项政策,这将为下一次实验测定产生一批候选物。
搜索使 R(x) 最大化的 x 是不够的,因为我们希望为一批查询采样具有高 R 值的一组代表性 x,即围绕 R(x) 的模式。请注意,存在获得多样性的替代方法,例如,使用批量贝叶斯优化(Kirsch 等人,2019)。所提出的方法的一个优点是计算成本与批次的大小呈线性关系(与比较候选对的方法相反,这至少是二次的)。由于可以使用合成生物学对十万个候选物进行分析,线性缩放将是一个很大的优势。
因此,在本文中,我们专注于将给定的正奖励或回报函数转换为生成策略的特定机器学习问题,该策略以与回报成正比的概率进行采样。在上面提到的应用中,我们只在生成一个候选后才应用奖励函数,即除了终端状态外,奖励为零,返回的是终端奖励。我们处于 RL 所谓的情节环境中。
我们的方法将给定状态下分配给动作的概率视为与节点为状态的网络相关联的流,而该节点的输出边是由动作驱动的确定性转换。进入网络的总流量是终端状态(即分区函数)中奖励的总和,可以显示为根节点(或开始状态)的流量。我们的算法受到 Bellman 更新的启发,并在流入和流出每个状态的流入和流出流量匹配时收敛。选择一个动作的概率与对应于该动作的输出流成正比的策略被证明可以达到预期的结果,即采样一个终端状态的概率与其奖励成正比。
此外,我们表明由此产生的 RL 设置是离策略的;即使训练轨迹来自不同的策略,只要它有足够大的支持,它也会收敛到上述解决方案。本文的主要贡献如下:
• 我们提出了 GFlowNets ,这是一种基于流网络和本地流匹配条件的非归一化概率分布的新生成方法:进入状态的流必须匹配输出流。
• 我们证明了 GFlowNets 的关键特性,包括流匹配条件(许多训练目标可以提供)与生成的策略与目标奖励函数的匹配结果之间的联系。我们还证明了它的离线特性和渐近收敛性(如果训练目标可以最小化)。此外,我们还证明了Buesing 等人之前(2019 年)将生成过程视为一棵树,当存在许多可导致相同状态的动作序列时,该工作将失败。
• 我们在合成数据上证明了从寻求一种回报模式,而是寻求对整个分布及其所有模式进行建模的有用性。
• 我们成功将 GFlowNet 应用于大规模分子合成领域,并与 PPO 和 MCMC 方法进行了对比实验。
今天,我想向大家介绍一种用于科学发现的新机器学习工具 GFlowNets。在人们所谓的黑盒优化,或者应该称为黑匣子探索的背景下,GFlowNets 可以应用于科学发现的许多领域,比如,发明新药物、发现新材料或者探索未知黑盒过程的良好控制设置。

我采用这种方法的动机之一,是在因果发现的背景下发现良好的因果模型和对观察的良好解释。在这些环境中,我们拥有一个 oracle,或一个黑匣子,或现实世界,或一个实验装置,我们可以对它进行查询,进行试验,或者可以尝试输入 x 的一些配置。
这些输入是查询 x,它们进入这个黑匣子,然后我们得到一个输出 f(x)。f 是一个标量,是我们选择的 x 的好坏指标。例如,一种分子的某个性质有多好?答案一般通过实验分析得到。我们不知道 f 里面发生了什么,但我们想找到 f 的高值。也就是说,我们想找到使得 f 很大的 x。更一般地说,我们希望获得大量好的解决方案。
这里还涉及到一个“多样性”的概念,以及一个“探索”的概念,因为我们将能够通过许多路由多次查询该 oracle。
最初,当我们不太了解 f 时,我们更多处于探索模式。我们将尝试不同的 x 值,并让学习器对 f 内部发生的事情有所了解。在这些过程即将结束时,从而获得有限信息时,我们可能更多处于强化学习的“利用”模式
因此,这种方法与强化学习之间存在联系,但也存在差异,并与主动学习有关。经典的主动学习,也称为基于池的主动学习(Pool-based Active Learning),就是这样工作的。我们有一个像上述一样的 oracle,它是一个从输入 x 到某个标量的函数。我们也有一个例子池 s,我们不知道答案,并希望调用 oracle 来找出答案。

所以在主动学习的每个阶段,学习器都会主动提出问题。而在传统的机器学习中,我们只是观察一组例子,然后从中学习。
在这里,除了已有的例子,我们还可以提出问题。例如,“对于一张图片,正确的标签是什么?”这就是主动学习。
这种方法的问题在于,在许多情况下,我们并没有一组固定的x配置。相反,我们希望能够在高维空间中提出任何问题,但这又可能遭遇指数爆炸。
我们从主动学习文献中学到的重要教训是如何选择这些查询,这里的基本思想是:我们想要估计预测变量f的不确定性。换句话说,对于要估计的函数,我们希望选择能够提供尽可能多信息的问题。
正如我所说,基于池的主动学习的问题是无法穷举,例如,无法穷举所有的分子,然后只需查询那些具有高不确定性的分子。我们需要以某种方式处理数量呈指数级增长的可能问题。
所以,我提议遵循的原则是生成式主动学习(Generative Active Learning),这是本次演讲最重要的内容,当学习器可以选择其希望现实世界提供答案的问题时,应该进行哪些实验?
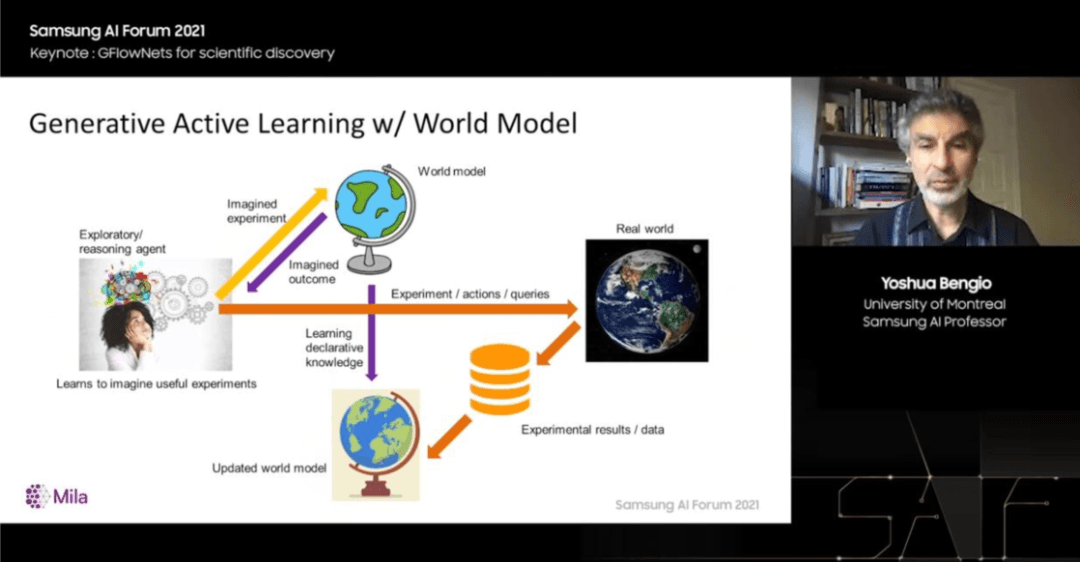
在高维空间中,一个不错的方案是:训练一个生成模型,该模型将对好问题进行采样。
要怎么训练这个模型呢?首先,我们观察现实世界,然后提出一些问题,接下来进行一些实验,将这些实验结果加载到一个数据集中。
因此,有了该数据集,我们就可以进行传统的机器学习方法。我们可以学习一个模型,比如给定 x 预测 y,我们也可以使用该模型来筛选潜在问题。
根据该模型,如果我们发现一个问题得分很高,比如很高的不确定性,那么这可能是一个好问题。
正如我所说,困难在于潜在的问题太多了。因此,仅凭预测候选实验的好坏程度是不够的,所以我们要训练这个生成模型。不过,我们将以一种与通常的生成模型不太相同的方式来训练它。
通常的训练生成模型的方式是利用一组固定的例子。但在这里,我们有一个由世界模型计算的函数,它会告诉我们特定的实验有多大用处。我们将采用这种特殊的方式来训练生成模型,寻找生成具有高f值的配置。
可能有很多方法可以做到这一点,但如果目标不仅仅是优化,而是找到不同的好的解决方案,那么合理的做法就是将分数换算。接下来,我们将基于世界模型获得一种奖励函数,使得生成模型不是最大化奖励,而是获得具有高回报的样本问题。

因此,以与奖励成正比的概率对它们进行采样。可以定义任何我们想要的奖励,那么这个解决方案就合适了。但现在有一个数学问题:如何将奖励函数转换为生成模型,使得这个生成模型可以以与该奖励函数成正比的概率进行采样?
原则上,我们可以将该函数写下来。P_T(x) 是从生成模型中采样的概率,应该等于 R(x) ,即对所有可能的奖励进行归一化。但归一化是很困难的,这是我们首先遇到的问题。概率工具箱中有一个工具原则上可以做到这一点,它被称为蒙特卡罗马尔科夫链。
唯一的问题是,在这些高维空间中,对于我们通常关心的数据类型,这种 MCMC 方法可能非常慢,事实上,由于所谓的模式混合挑战,很难真正找到一组多样化的解决方案。
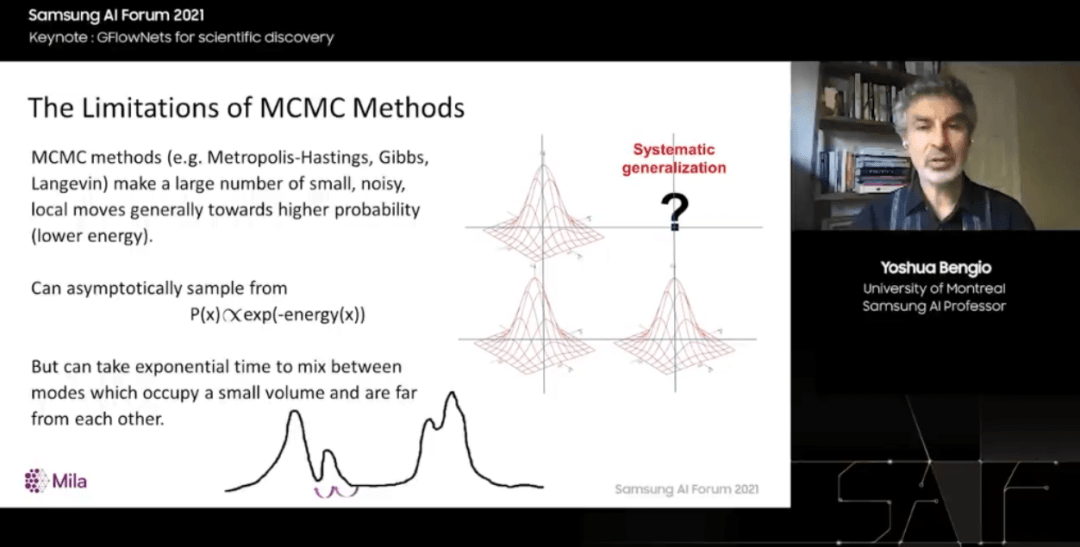
MCMC 方法的工作方式是从初始猜测开始。它们会对初始猜测做一些小改变,然后通常会接受或拒绝这些改变,这样我们就会倾向于朝着更可能的配置、更高的奖励配置迈进,如果用正确的数学方法做到这一点,最终,样本链就会收敛到来自正确分布的样本,但这个过程很长。
事实上,让这条链访问所有模式可能需要指数时间,或者先定位大部分模式是高概率奖励的区域。问题在于,当两种模式相距较远时,从一种模式切换到另一种模式可能需要花费大量时间,就像穿越沙漠一样。
如果是十年前,我会说这是不可行的。我们不能将 MCMC 应用于图像或分子之类的东西,或者有很多模式的高维物体,它们可以被大跨度分开,并且这些模式仅占据极小的体积,所以我们不能随便尝试。但现在有了机器学习方法,我们可以使用机器学习来代替这种积累试验而不从中提取有用信息的盲目过程。

因此,假设我们已经访问了三种模式,如我们在右侧所见。幸运的是,分布中有结构。事实上,学习器注意到我们发现的这三种模式都位于网格的点上。所以也许这个网格上的第 4 点是一个尝试的好地方。这就是泛化,或者实际上被称为系统泛化,我们在远离数据的地方进行泛化。
我们将使用机器学习从模式中泛化,通俗来说,我们基于它运行良好的地方看到的模式来猜测它运行良好的其他地方。我们一直在为此开发一种特殊的方法,我称之为 GFlowNets,生成流网络,这是一种生成模型。
它用于生成问题或结构化的对象,所以我们构造对象的方式是通过一系列动作。我们不是一次性生成,而是在一系列动作中生成。例如,在分子的情况下,将碎片添加到图形中,或者将值附加到一组高维值。
我们称其为生成流网络的原因是它的整个理论基于对非规范化概率的思考,哪些是流过路径的流,其中一条路径告诉我们如何构造一个问题,一个对象x。所有的路径都从一个根节点开始,到同步节点结束,但是有不同的概率——我们将去选择一些动作,然后选择其他动作。

如果看一下这个有向图,它的路径数量呈指数级增长。一般来说,以及我们想要获得的是,我们按比例对对象进行采样,对于给定的函数,是非归一化概率的数量,或在类似于终端边缘上流动——这是我们构造对象的最后一步,正是我们想要的奖励函数。所以在某种程度上,我们可以做的是修复这些流。
我们如何安排其他边缘的流?这意味着构建对象的策略,使得整个事物是一个流网络。如果我们能做到这一点,我们就会得到我们想要的,也就是说,采样对象的概率将与给定的奖励函数成正比。
这就是这张幻灯片要讨论的内容。这是一系列取自即将在线的技术报告的定义和命题,所有这些数学都表明流程是对应的。对于事件的非归一化概率,这些事件对应于轨迹上一组属性,告诉我们如何构造一个对象,因此我们也可以定义与这些流的比率相对应的传统概率。
最重要的是,这些流有局部条件,所以我们将学习一个流函数,学习一个新的网络,它输出一个数字,一种表示有多少流通过特定边缘或特定节点的分数。如果我们查看每个节点及其输入边和输出边,并且进入的流等于流出的流。如果所有节点都是如此,则流函数是正确的,它学到了一些东西,使整个包具有非常好的特性。
如果是这样,那么采样对象的概率将与该奖励函数成正比,并首先使流具有这些属性,它是特定点发生的事情的局部属性,我们将这些轨迹上的状态称为当我们构建这些对象时的状态。

我们可以定义一个名为流匹配训练目标的损失函数,还有其他可以定义的损失函数,但它们都是局部的,只是说在此处的状态 s_t 中一些流入的流应与退出的流的总和相匹配。好消息是,如果从强化学习的角度考虑,这个训练目标可以使用我们想要的任何方式采样的轨迹来应用,只要它们为所有可能的轨迹赋予非零概率。换句话说,这可以离线训练,不必使用来自根据网络流量访问的策略的样本进行训练。
现在,我想谈一些很酷的东西和意想不到的东西。如果我们对这些定义进行推广,那么我们的神经网络预测流入边缘或节点的流现在是有条件的,就像额外的变量输入。当然我们可以计算条件概率,并使用条件策略进行采样。

这有点微不足道,但出乎意料的是,当我们以轨迹本身发生的事件为条件时,例如,以在问题构建过程中遇到过的状态为条件,就可以计算一种现代化形式,也称为自由能。换句话说,这个新网络现在可以输出一个难以处理的数字。这意味着我们还可以计算条件概率,因为我们已经开始构建。我们处于动作序列中的特定点,可以计算和采样从动作序列下游到达其他一些状态的概率。
而且,事实上,我们可以用它来计算看起来难以处理的事情,例如熵、条件熵和互信息。所有这些难以处理的数量,你可能会问我们怎么可能计算出它们?如果与蒙特卡罗马尔科夫链进行比较,又如何?我们是否遇到了一个根本上难以解决的问题。这里可以根据能量函数或奖励函数对概率进行采样。我们已经把它变成了一旦网络经过训练就很容易的问题。

我们已经把一个棘手的问题变成了一个简单的问题。但是我们隐藏了训练本身的复杂性,也就是所有这些我说的可以计算的结果。我们可以用正确的概率进行采样,计算这些自由能和边缘化。
所有这些结果只有在我们能够训练 GFlowNet 的情况下才有可能。因此,如果我们试图学习的奖励函数中没有结构,就不可能了,正确训练这个网络可能需要指数级的时间。但是如果有结构,如果模式以一种学习器可以泛化的方式组织起来,那么就不需要访问整个空间。例如,如果我们可以猜测,如果查看 GAN 或 VAE 等等生成模型,它们会泛化到从未访问过的像素配置,并且不需要对其进行训练。
它们不需要在所有可能的像素配置上接受训练,就可以做到这一点。生成之所以发生是因为底层世界有结构。所以我们可以使用这些结构来潜在地边缘化高维联合概率。我们可以使用这些概率来表示图上集合的分布,因为图只是特殊类型的集合。
相关阅读 >>
最高支持12代酷睿处理器!华擎发布新一代deskmini迷你主机
暴雪嘉年华明年年初回归,《魔兽世界》发布2023年更新计划图
携程旅行改签客服电话2023今日更新曹操出行发布新车曹操60:续航可达415公里,可6
哈利波特:掌握对战的节奏?斯内普棋子流的攻势,令敌人防不胜防
更多相关阅读请进入《新闻资讯》频道 >>




