
输出的结果就是还未渲染的网页代码,即请求体的内容。可以查看响应头的信息:
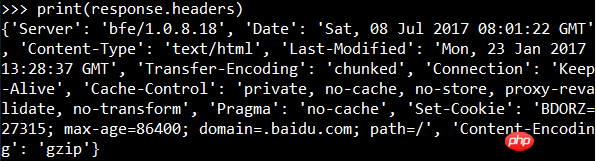
查看状态码:
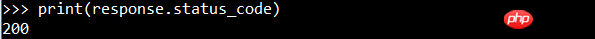
还可以将请求头添加到请求信息里面:
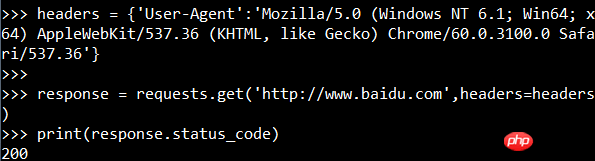
抓取图片(百度logo):

六、如何解决JavaScript渲染问题
使用Selenium webdriver

输入print(driver.page_source)可以看到,这次的代码是渲染之后的代码。
【备注】chrome浏览器的使用
F12打开开发者工具
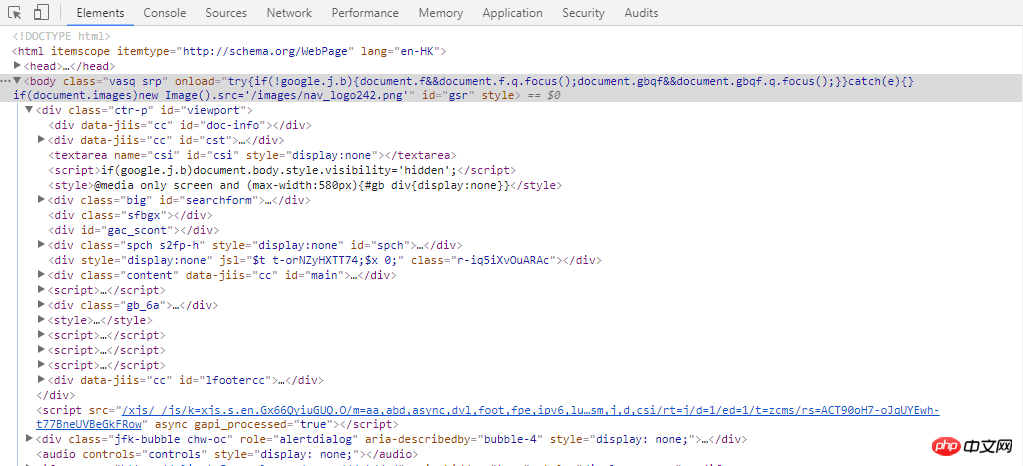
Elements标签显示了显然后的HTML代码。
Network标签
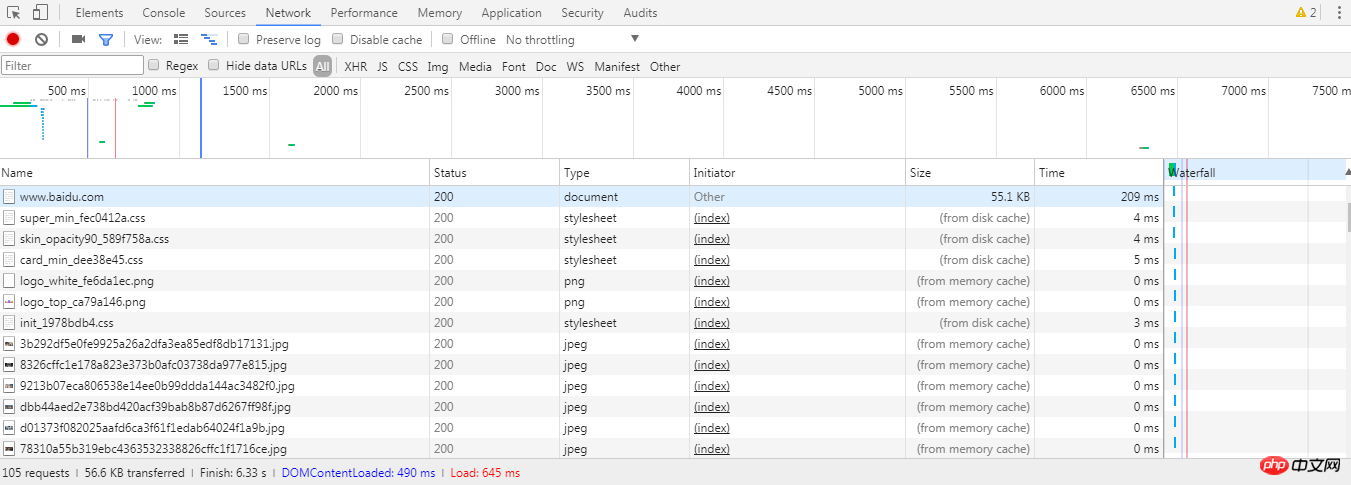
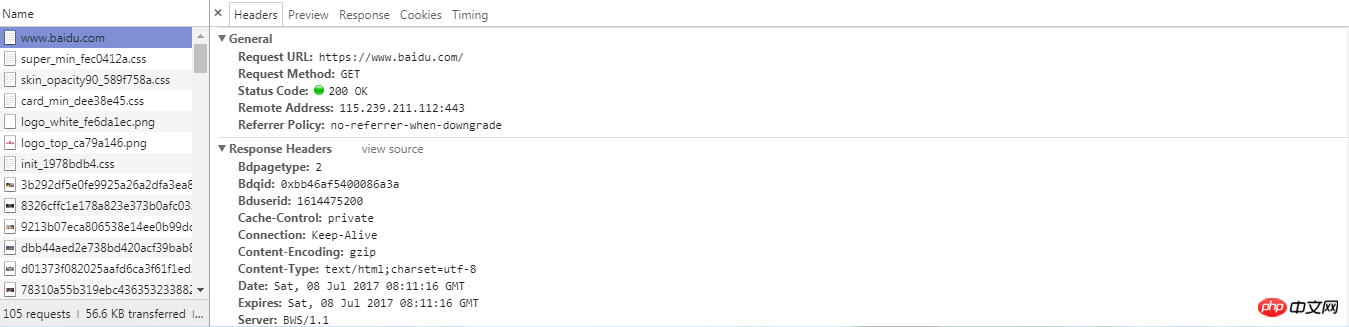
Network标签下有浏览器请求的数据,点开可以查看详细的信息,如上提到的request headers、response headers等等。
以上就是什么是爬虫?爬虫的基本流程是什么?的详细内容,更多文章请关注木庄网络博客!!
相关阅读 >>
更多相关阅读请进入《Python》频道 >>

Python编程 从入门到实践 第2版
python入门书籍,非常畅销,超高好评,python官方公认好书。




