都知道索引有助于快速检索,但为什么用了索引之后,查询就会变快?
最常见的索引是 B+ Tree 索引,索引可以加快数据库的检索速度,但是会降低新增、修改、删除操作的速度,一些错误的写法会导致索引失效等等。
但是如果被问到,为什么用了索引之后,查询就会变快?
B+ Tree 索引的原理是什么?
这时候很多人可能就不知道了,今天我就以 MySQL 的 InnoDB 引擎为例,讲一讲 B+ Tree 索引的原理。
索引的基础知识
MySQL 的基本存储结构是页,大概就是这个样子的:
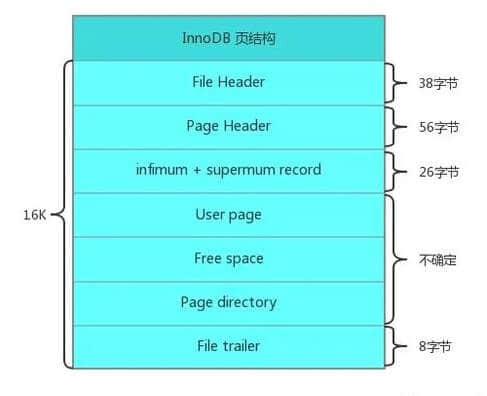
在这里,我们需要了解以下几点(非常重要):
当我们用 MySQL 的 InnoDB 引擎创建表,有且只能有一个主键;
如果我们没有显示地指定之间,那么MySQL 会自动生成一个隐含字段作为主键;
聚集索引:以主键创建的索引;聚集索引的叶子节点存储的是表中的数据;
非聚集索引:非主键创建的索引;非聚集索引在叶子节点存储的是主键和索引列;使用非聚集索引查询数据,会查询到叶子上的主键,再根据主键查到数据(这个过程叫做回表)。
页和页之间、页和数据之间的关系
我们以聚集索引做讲解,页和页之间、以及页和数据之间的关系是这样的:
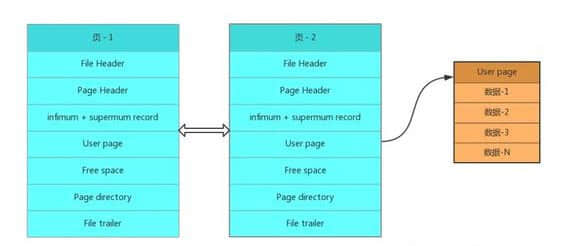
数据页和数据页之间,组成一个双向链表;
每个数据页中的记录,是一个单向链表;
每个数据页都根据内部的记录生成一个页目录(Page directory),如果是主键的话,可以在页目录中使用二分法快速定位;
如果我们根据一个非主键、非索引列进行查询,那么需要遍历双向链表,找到所在的页;
再遍历页内的单向链表;
如果表内数据很大的话,这样的查询就会很慢。
B+ Tree 索引的原理
先让我们看看 B+ Tree 索引大概是什么样子(以聚集/主键索引为例):
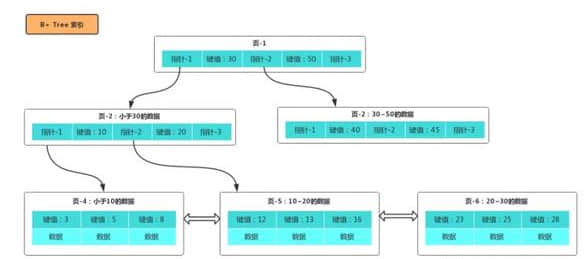
假如这时候我们要查询 id = 16 的数据:
查询页-1,找到页-2 存储的是小于 30 的数据;
查询页-2,找到页-5 存储的是 10~20 的数据;
查询页-5,找到 id = 16 的数据。
很显然,没有用索引的时候,需要遍历双向链表来定位对应的页,而有了索引,则可以通过一层层“目录”定位到对应的页上。
为什么 B+ Tree 索引会降低新增、修改、删除的速度
B+ Tree 是一颗平衡树,如果对这颗树新增、修改、删除的话,会破坏它的原有结构;
我们在做数据新增、修改、删除的时候,需要花额外的时间去维护索引;
正因为这些额外的开销,导致索引会降低新增、修改、删除的速度。
现在你是否理解了 B+ Tree 索引的原理?
相关阅读 >>
更多相关阅读请进入《索引》频道 >>

数据库系统概念 第6版
本书主要讲述了数据模型、基于对象的数据库和XML、数据存储和查询、事务管理、体系结构等方面的内容。




