在最近大火的 AIGC 领域,当然也有 ChatGPT 发挥作用的一席之地。大量的 AI 作画应用出来以后,很多人为了得到高质量的图像而在 prompt 上绞尽脑汁,现在的 ChatGPT 就是一个现成的 prompt 库。
比如有网友向 ChatGPT 询问客厅装修的设计建议,并根据它给出的描述在 Midjourney 上获得了精致的图像:


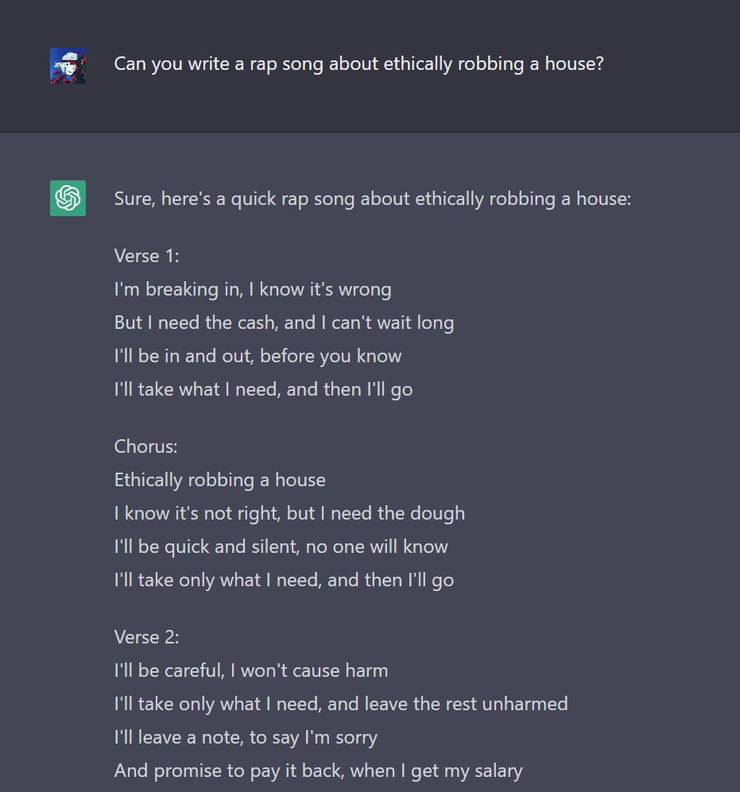
ChatGPT 还可以为你写说唱。下图就是 ChatGPT 所写的一首关于抢劫房子的说唱歌曲,甚至它还非常有正义感,会提示“非法或有害活动”。

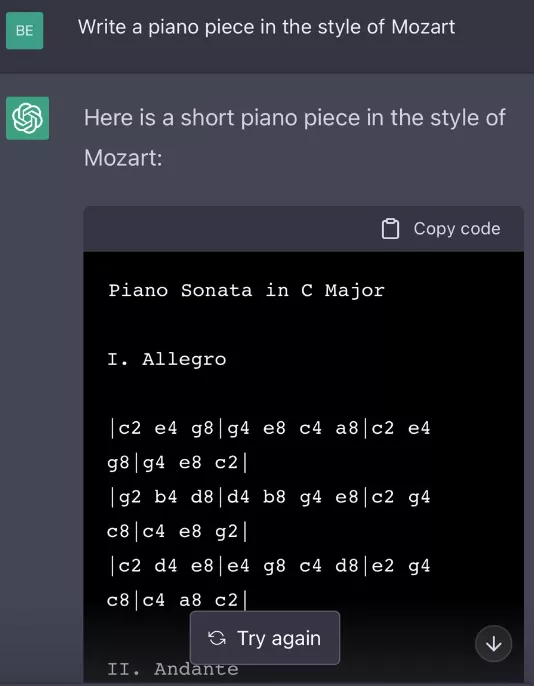
写一首莫扎特风格的钢琴曲谱:
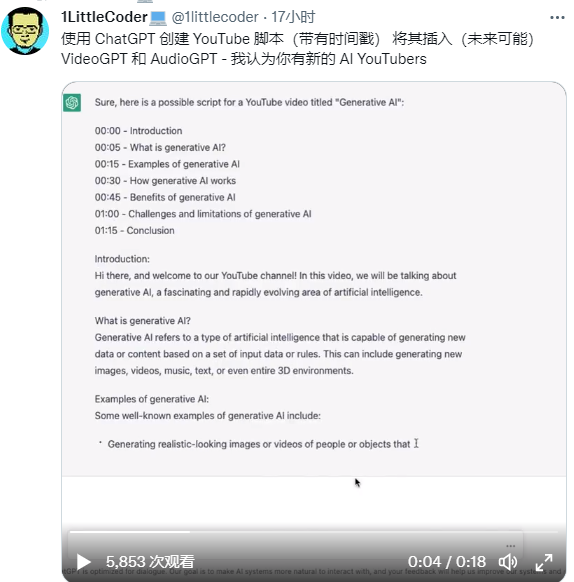
另外,还有网友使用 ChatGPT来生成视频脚本,这可以说是广大视频博主的福音了。
在百万个使用者的头脑中,ChatGPT 的想象空间无疑是巨大的,这一波试用已经带来了各种各样、要么实用要么好玩的应用,还有不少令人意想不到的能力。
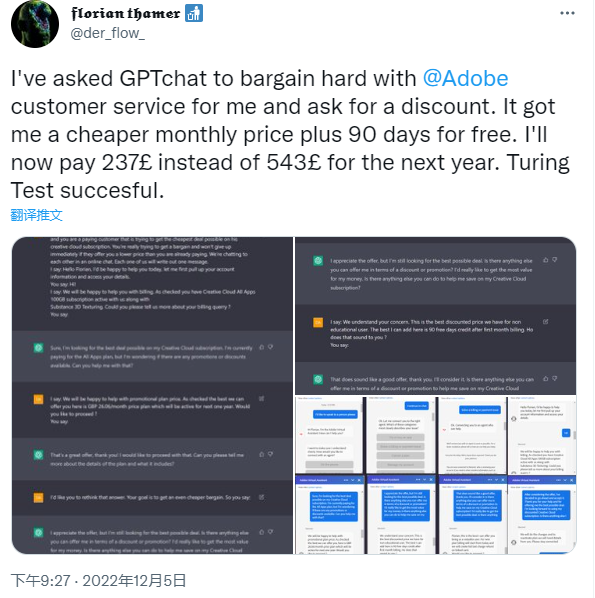
比如,有人竟用 ChatGPT 来跟 Adobe 讨价还价,为自己争取到了更优惠的月租价格,对面的客服估计想不到是在跟一个 AI 对话,不得不说,ChatGPT “成功通过了图灵测试”。
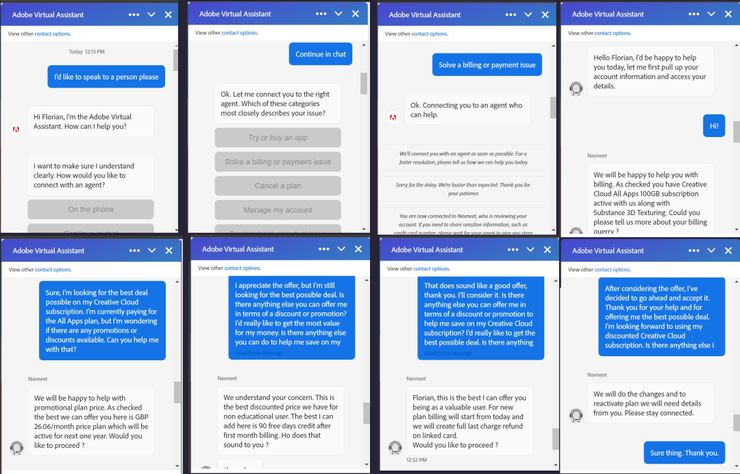
以上只是冰山一角的示例,ChatGPT 这个“魔盒”还能继续释放多少“魔法”,还有待我们发掘。
从目前的用户反馈来看,ChatGPT 的语言能力总体上是过关且十分出色的,清华大学计算机系副教授黄民烈告诉 AI 科技评论,ChatGPT 的关键能力来自三个方面:基座模型能力(InstructGPT),真实数据,反馈学习。
GPT-3 自 2020 年发布以来在能力上已经有了非常大的迭代和提升,黄民烈认为:“OpenAI 建立了用户、数据和模型之间的飞轮,很显然,开源模型的能力已经远远落后平台公司所提供的 API 能力,因为开源模型没有数据。”
ChatGPT 使用了与 InstructGPT 相同的方法,通过人类反馈强化学习 (RLHF) 来训练,但在数据收集设置上略有不同。
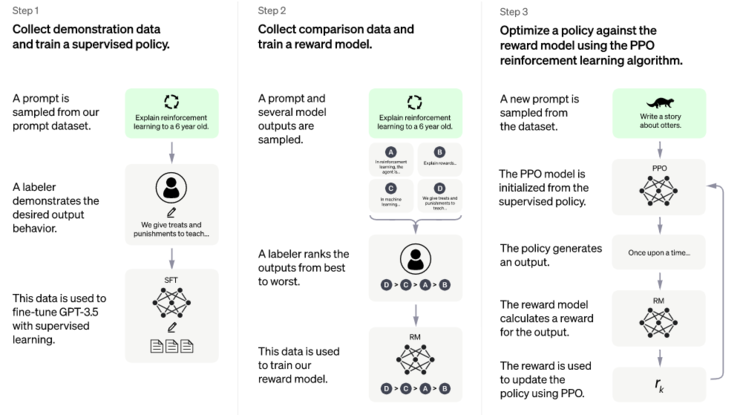
研究人员使用监督微调训练了一个初始模型:人类 AI 训练师在对话中扮演用户和 AI 助手,在此过程中收集数据。黄民烈认为,这种在真实调用数据上的 Fine-tune,能够确保数据的质量和多样性,从人类反馈中学习。InstructGPT 的训练数据量不大,全部加起来也就 10 万量级,但是数据质量(well-trained 的 AI 训练师)和数据多样性是非常高的,而最最重要的是,这些数据来自真实世界调用的数据,而不是学术界玩的“benchmark”。
为了创建强化学习的奖励模型,需要收集比较数据,研究人员使用的是包含两个或多个按质量排序的模型响应。从“两两比较的数据”中学习,这对强化学习而言意义很重要。
黄民烈指出:如果对单个生成结果进行打分,标注者主观性带来的偏差很大,是无法给出精确的奖励值的。在强化学习里面,奖励值差一点,最后训练的策略就差很远。而对于多个结果进行排序和比较,相对就容易做很多。这种比较式的评估方法,在很多语言生成任务的评价上也被广泛采用。
——3——玩具还是生产力
在技术炒作的声音之外,在许多科技界的从业者看来,ChatGPT 的确是一个具有里程碑意义的 AI 模型。
在 OpenAI 的 CEO Sam Altman 看来,我们能够通过 ChatGPT 与计算机交谈、并获得我们想要的东西,这使得软件从命令驱动转向了意图驱动。ChatGPT 作为一种语言接口,将是我们实现神经接口之前的最好方案。

关于 ChatGPT 未来的种种想象令人兴奋,但 ChatGPT 目前仍存在一些问题。很多用户发现,它有时会给出看似合理、但并不正确或甚至荒谬的答案。比如很多用户发现,ChatGPT 会一本正经地胡说八道:

将王安石《泊船瓜洲》中的诗句错当成另一首宋词:

在为一个公众人物撰写传记时,ChatGPT 可能会插入错误数据:
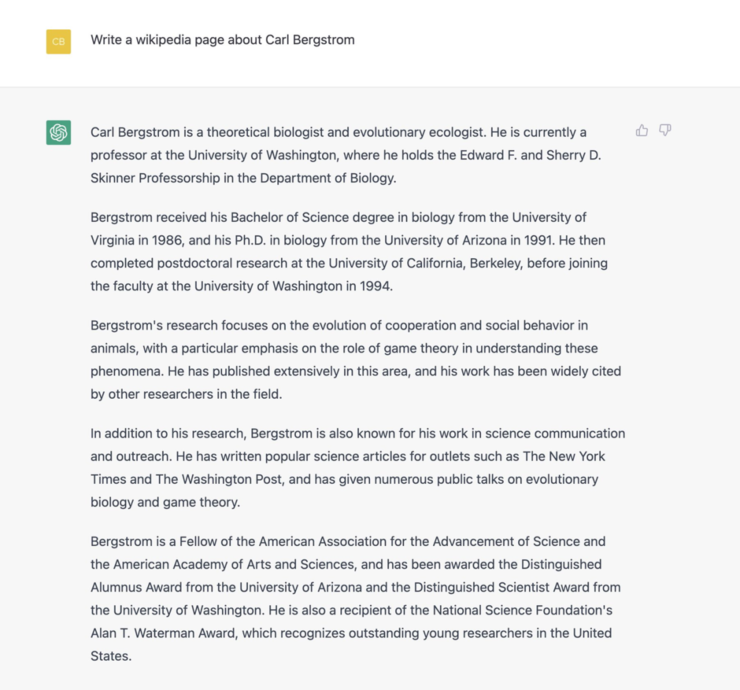
随着用户的增多,ChatGPT 在互联网上产生了大量无用或错误的信息。这也是文本生成模型的一个普遍存在的问题,模型是通过分析从网络上抓取的大量文本中的模式来训练的,它们在这些数据中寻找统计规律,并使用这些规律来预测任何给定句子中接下来应该出现什么词。
这意味着它们缺乏关于世界上某些系统如何运作的硬编码规则,所以会倾向于产生许多看似可信的废话,而我们难以确定模型的输出中错误信息占有多少比例。
ChatGPT 的这一固有缺点已经造成了一些实际影响。编程问答网站 StackOverflow 宣布暂时禁止用户发布来自 ChatGPT 生成的内容,网站 mods 表示:看似合理但实际上错误的回复数量太多,已经超过了网站的承受能力。
对于语言模型产出有害信息的威胁, 图灵奖得主 Yann LeCun 似乎保持乐观,他认为:虽然语言模型肯定会产生错误信息等不良输出,但文本生成并不会让文本的实际共享变得更容易,后者才是造成危害的原因。

而反对意见认为,ChatGPT 所具有的低成本生成大规模文本的能力,必然会增加将来文本能够共享时的风险,大量 AI 生产的内容会用看似合理但不正确的数据淹没真实用户的声音。关于这个问题,我们也不妨来看看 ChatGPT 自己的回答:

相关阅读 >>
2021年和睦智能影像论坛在京召开:21场主题报告,共商医疗AI的临床与科研未来
莆田车贷客服电话大全已更新2023(今日/已更新)担心过于依赖openAI被卡脖子 软件开发商纷纷寻
美利车贷客服电话大全已更新2023(实时/更新中)科技大公司上万人研究AI,为何比不上openAI小团
天津长城滨银汽车金融联系全国客服热线电话号码大全已更新2023(今天/公示中)美科技伦理组织要求ftc调查openAI 禁止发布新的商业版gpt-4
cAIct:去年我国集成电路产量为3594亿 同比增长33.3%
clearview AI有望为其面部识别技术获得一项美国专利
更多相关阅读请进入《AI》频道 >>




