本文摘自php中文网,作者coldplay.xixi,侵删。

之前在网上也写了不少关于爬虫爬取网页的代码,最近还是想把写的爬虫记录一下,方便大家使用吧!
代码一共分为4部分:
第一部分:找一个网站。
1 2 |
|
这里大家可能会有一些库没有进行安装,先上图让大家安装完爬取网页所需要的库,其中我本次用到的库有:bs4,urllib,xlwt, re。
(免费学习推荐:python视频教程)
如图
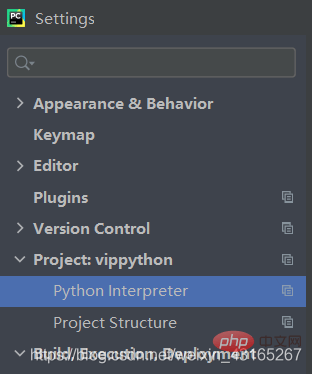
这里选择file-setting-Project-然后选择左下角的加号,自行去安装自己所需要的文件就可以了。
下面的代码是爬取网页的源代码:
1 2 3 4 5 6 7 8 |
|
第二部分:爬取网页。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
|
第三部分:得到一个指定的url信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
第四部分:保存数据
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
这里大家看一下代码,关于代码的标注我写的还是挺清楚的。
其中关于学习这个爬虫,还需要学习一些基本的正则表达式,当然python基本的语法是不可少的希望对大家有帮助吧。
相关免费学习推荐:python教程(视频)
以上就是介绍python爬取网页的详细内容,更多文章请关注木庄网络博客!!
相关阅读 >>
Python中@property装饰器的技巧性用法(代码示例)
更多相关阅读请进入《Python》频道 >>

Python编程 从入门到实践 第2版
python入门书籍,非常畅销,超高好评,python官方公认好书。




