本文摘自php中文网,作者coldplay.xixi,侵删。

免费学习推荐:python视频教程
xpath–简单的爬虫实例–提取阴阳师原画壁纸
文章目录
一、前言
很多人都玩过阴阳师吧,别的不谈,阴阳师的原画制作的那是相当地精细,闲暇之余,用几行简单的代码爬取下来,岂不美哉?
二、需要用到的库
1 | import requestsfrom lxml import etreefrom fake_useragent import UserAgentimport os
|
没用安装库的小伙伴,可以看一下我之前写的这篇文章,里面有很多国内源的链接,方便你的下载。
传送门
三、实现过程
1、分析网页
首先打开官网,官网传送门,点击“视听中心”里面的“原画壁纸”
进入到原画壁纸页面后,选择一个壁纸,进行检查。
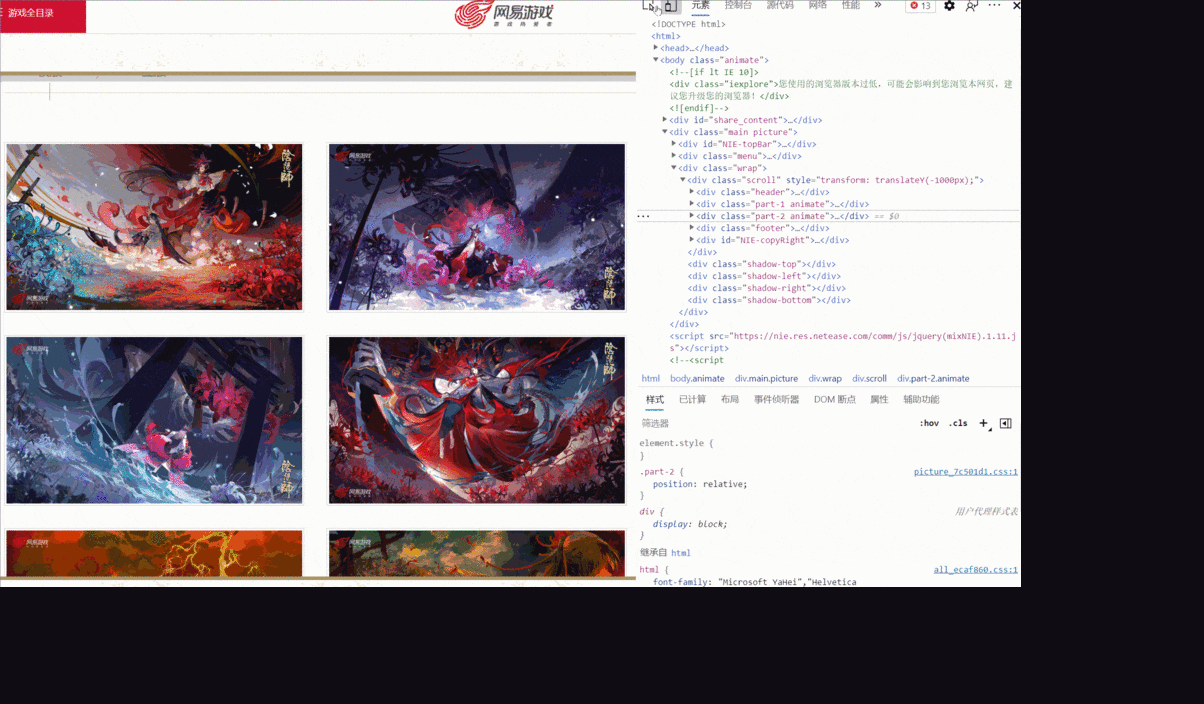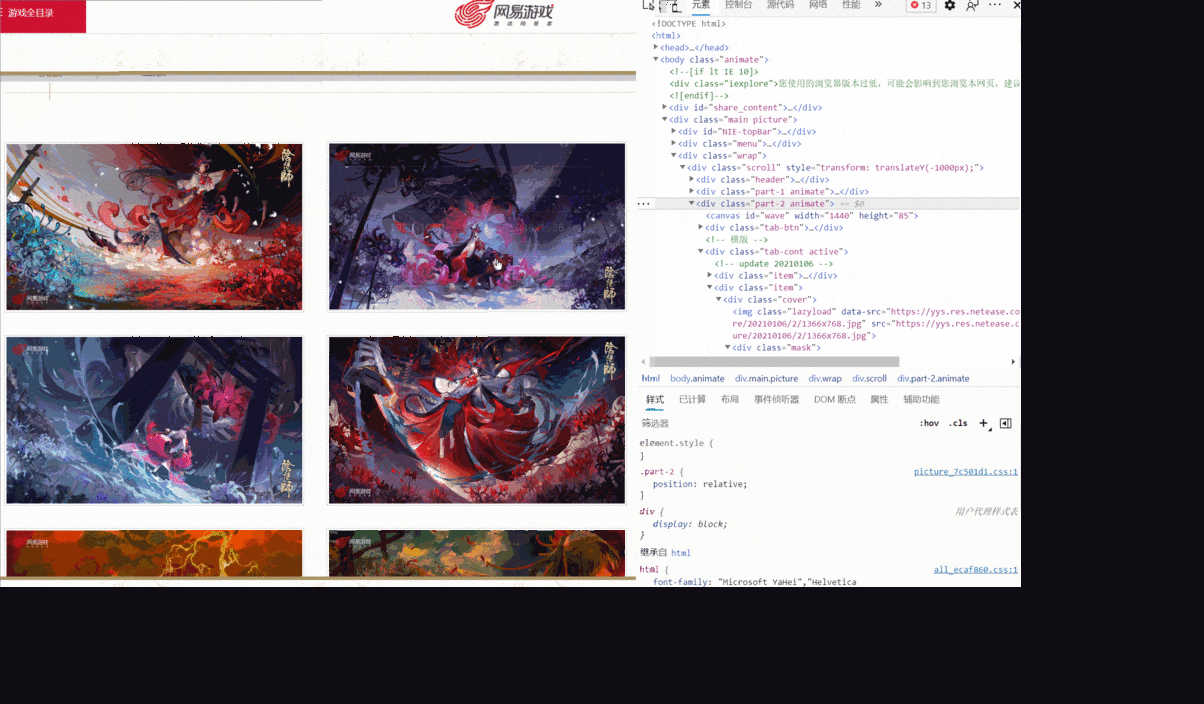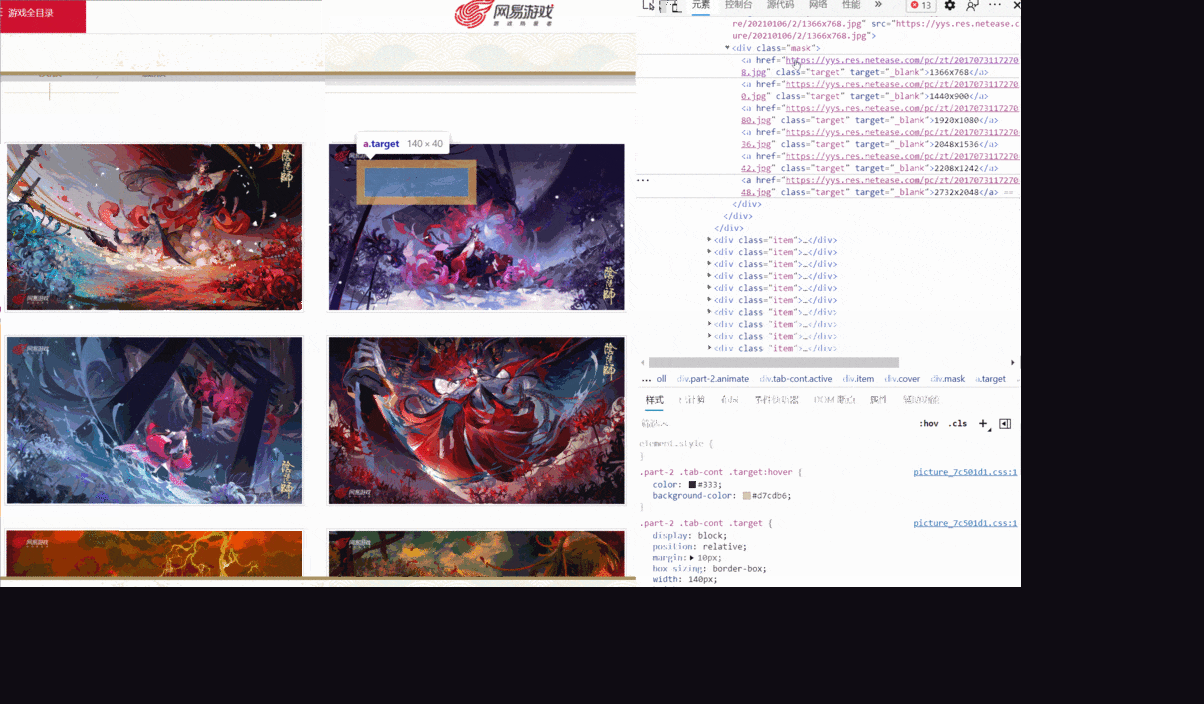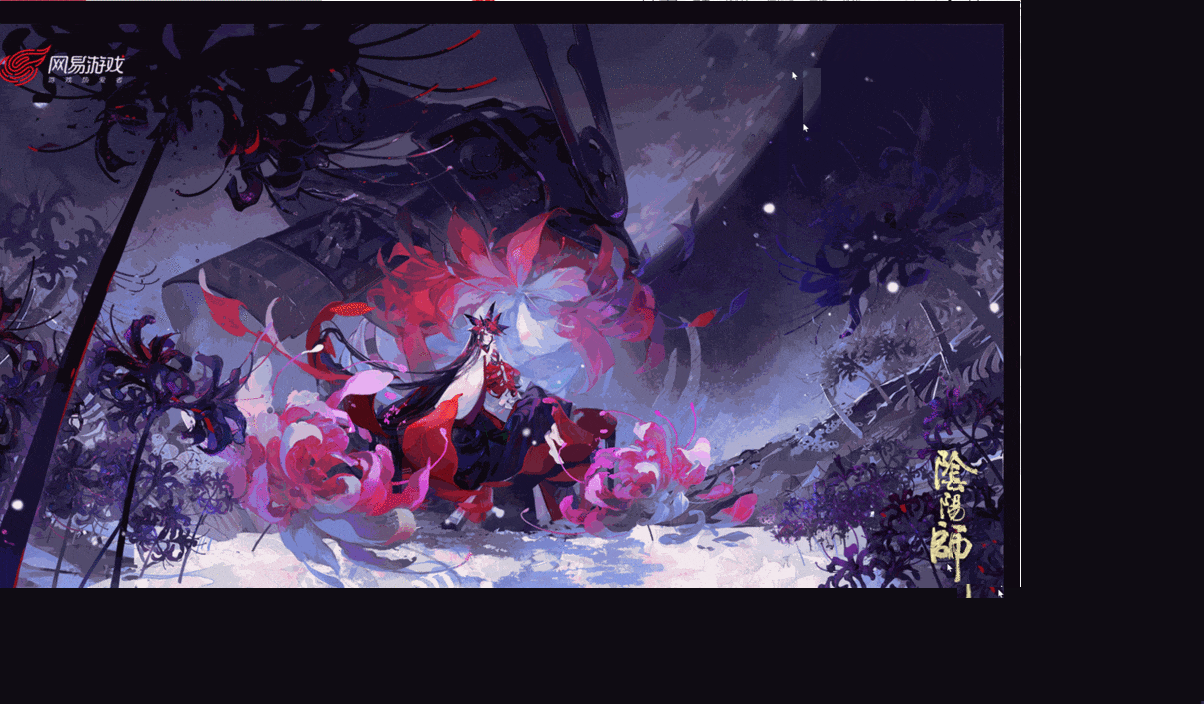
我发现,对于不同的分辨率,有不同的链接对应,而我检查的这张图有六个分辨率,是不是所有的图片都是这样呢?
后来我发现,并不是!
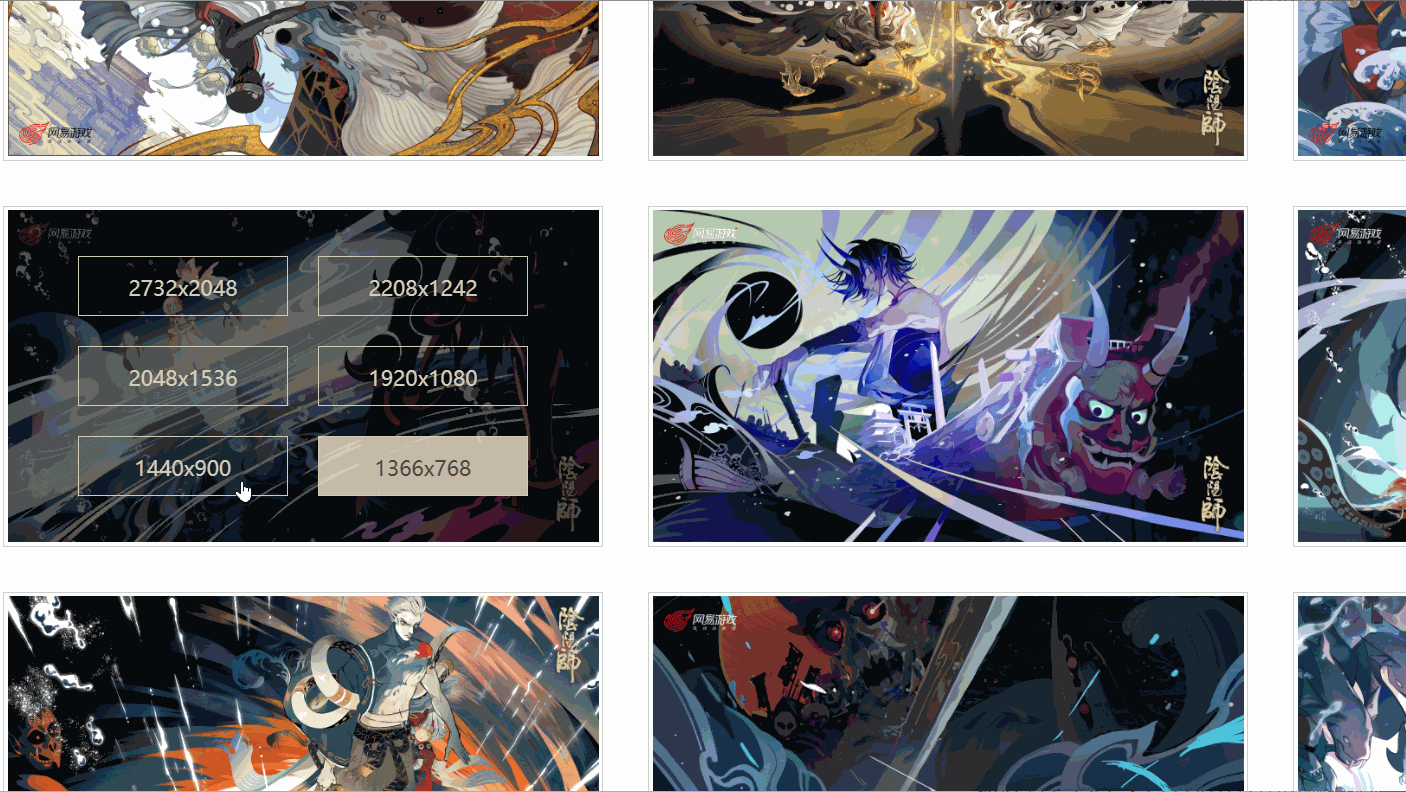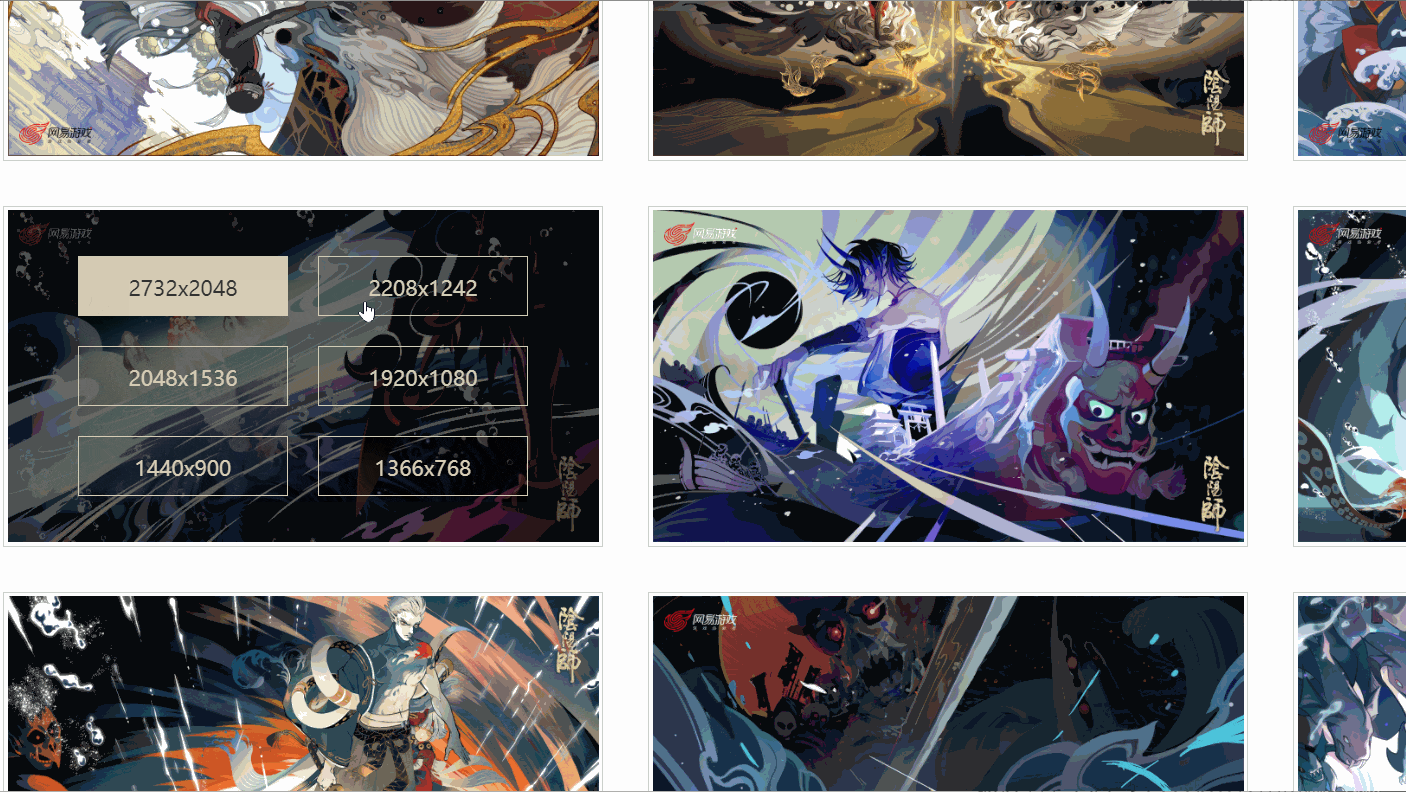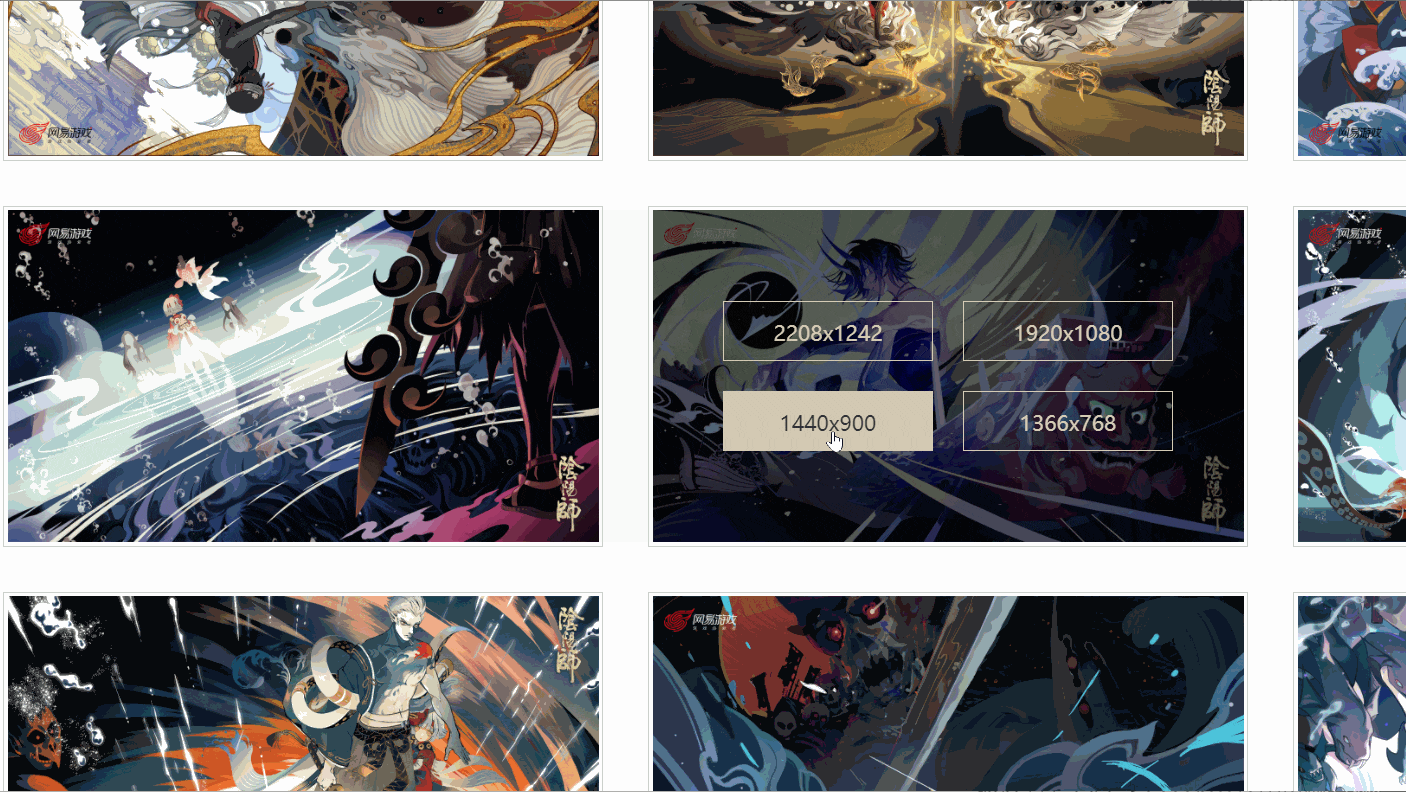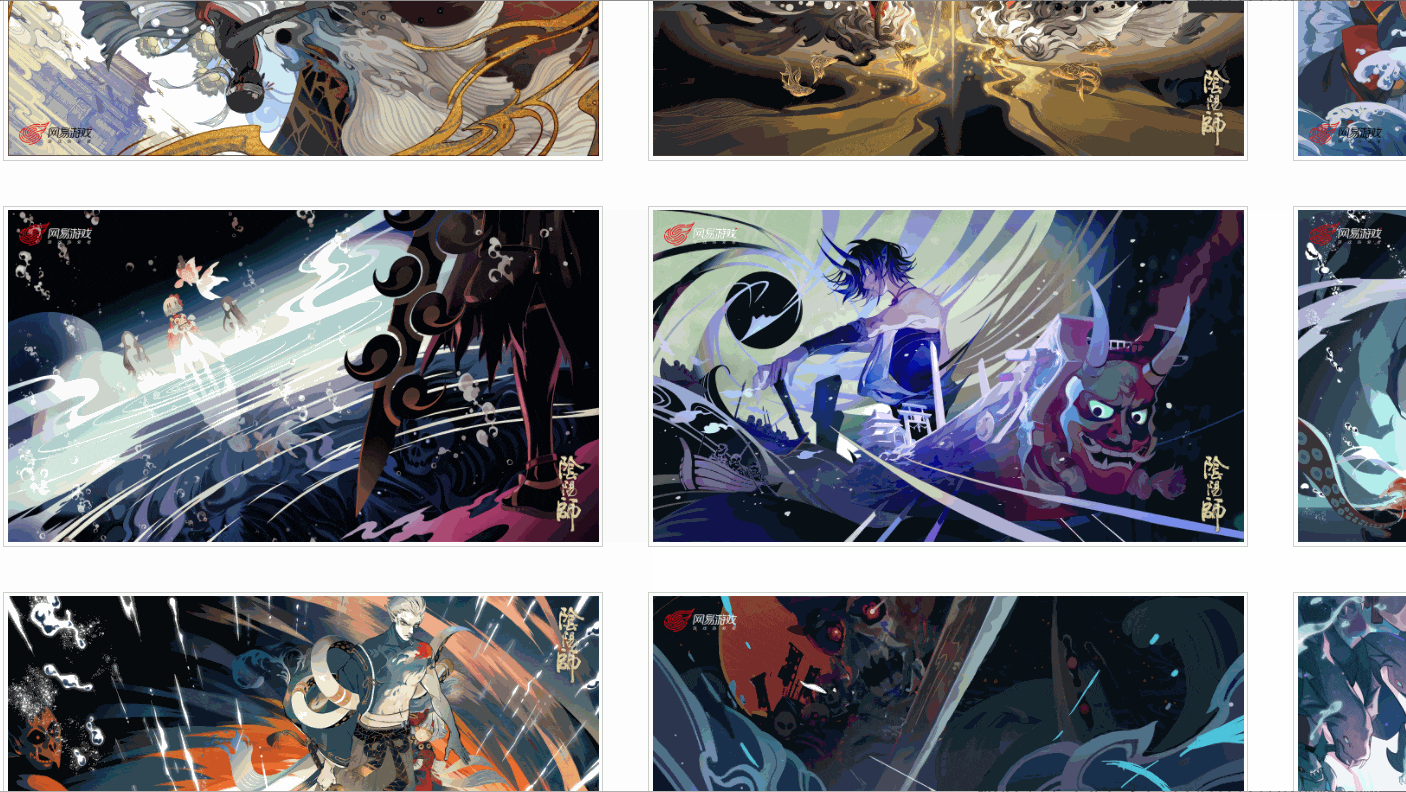
如上所示,有个图甚至只有四个分辨率,并且,每张图的分辨率的位置对应还不一致,那该怎么提取原画链接呢?
A:利用xpath,根据文本内容提取节点
1 | a = lists[i].xpath('./p/p/a[contains(text(), "1920x1080")]')[0]
|
这样就能提取到分辨率为“1920x1080”的a节点了。
Q:lists[i]是什么?
A:看了完整代码就知道了。
2、完整代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import requestsfrom lxml import etreefrom fake_useragent import UserAgentimport os
path = 'D:/阴阳师'if not os.path.exists(path):
os.mkdir(path)# 随机产生请求头ua = UserAgent(verify_ssl=False, path='fake_useragent.json')url = 'https://yys.163.com/media/picture.html' # 原画壁纸的页面链接response = requests.get(url=url).text
html = etree.HTML(response)lists = html.xpath('/html/body/p[2]/p[3]/p[1]/p[3]/p[2]/p')num = 1for i in range(len(lists)):
a = lists[i].xpath('./p/p/a[contains(text(), "1920x1080")]')[0] # 根据文本内容锁定节点a
image_url = a.xpath('./@href')[0] # 获取原画壁纸链接
image_data = requests.get(url=image_url).content
image_name = '{}.jpg'.format(num) # 给每张图片命名
save_path = path + '/' + image_name # 图片的保存地址
with open(save_path, 'wb') as f:
f.write(image_data)
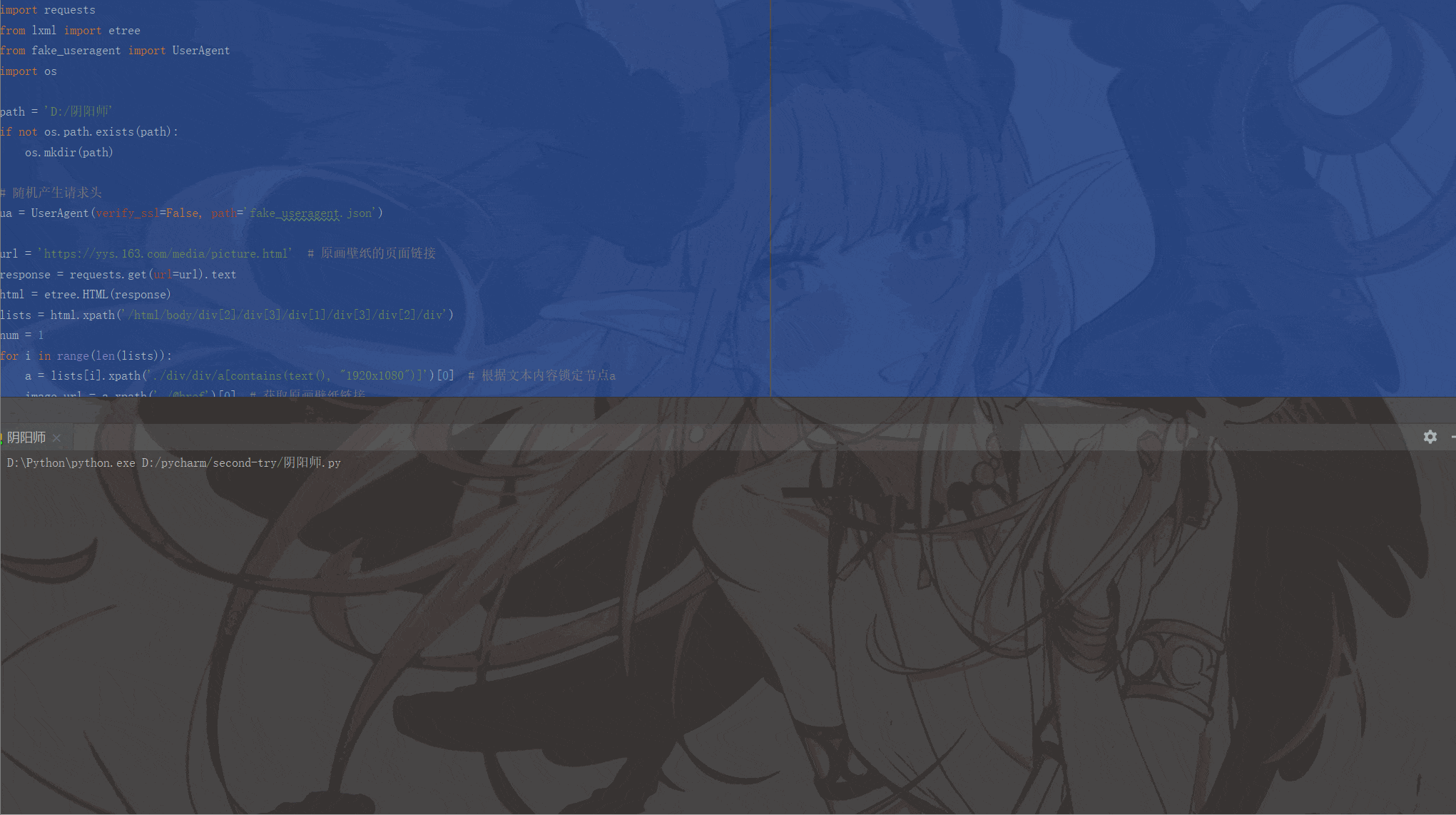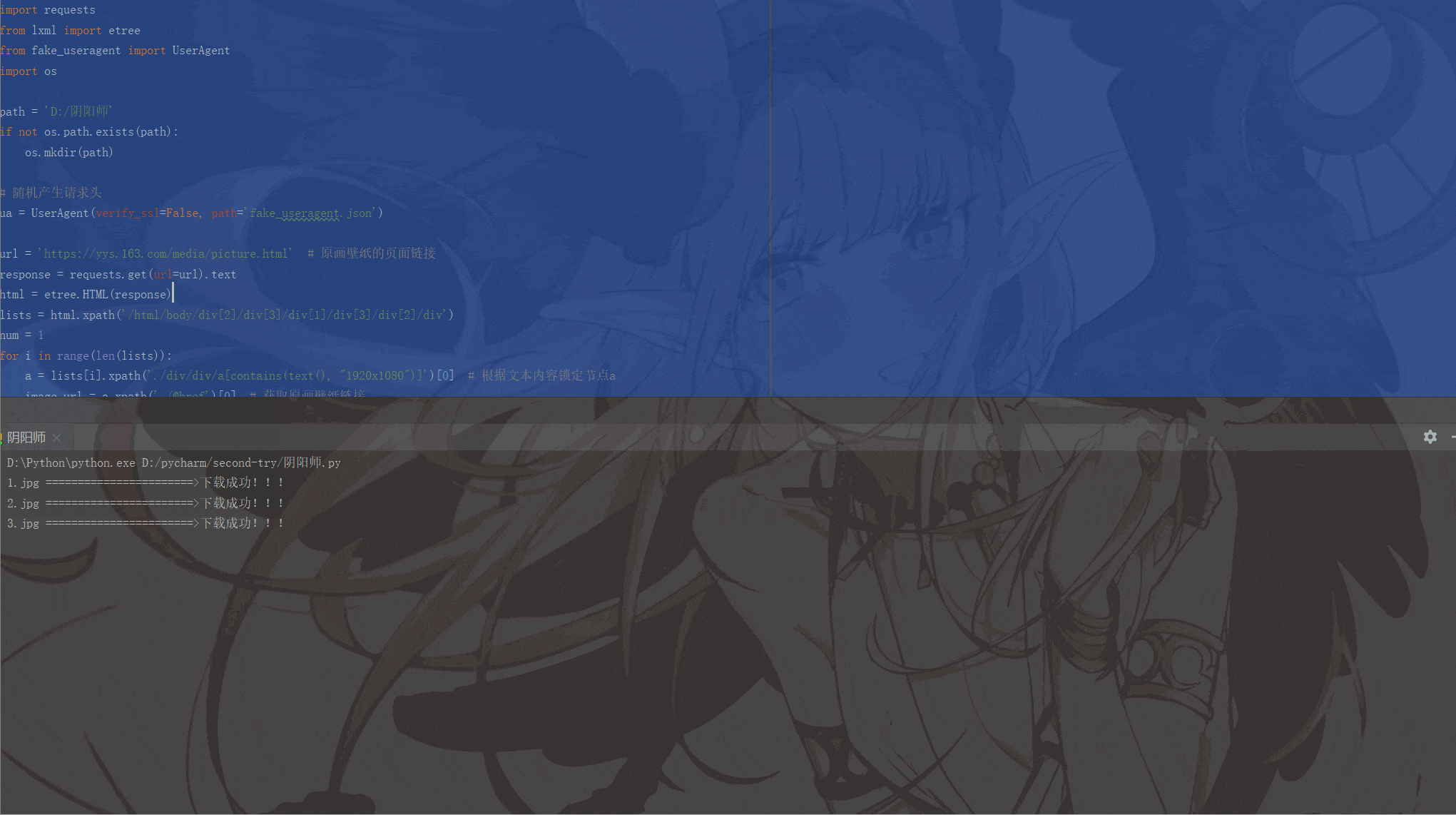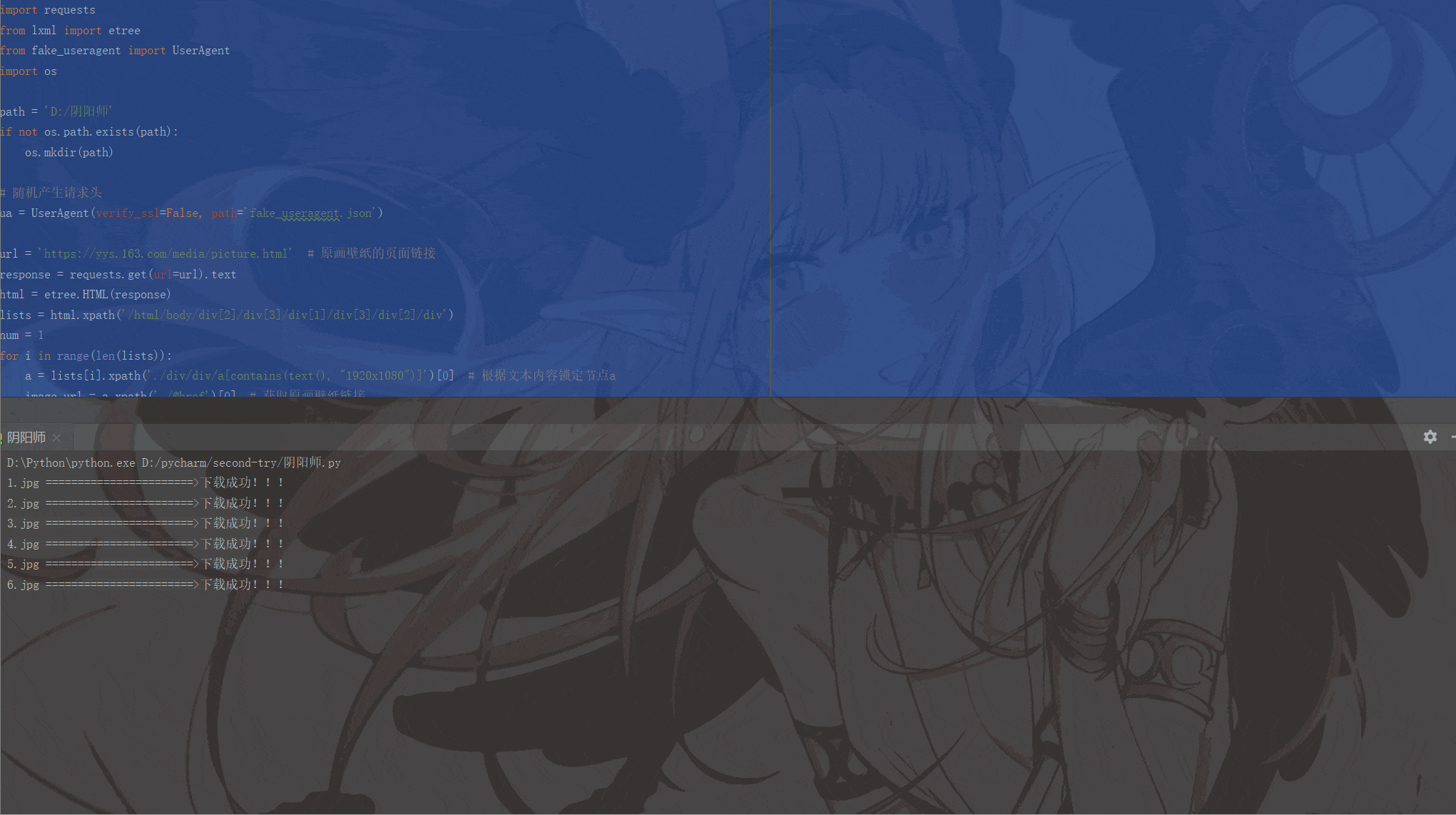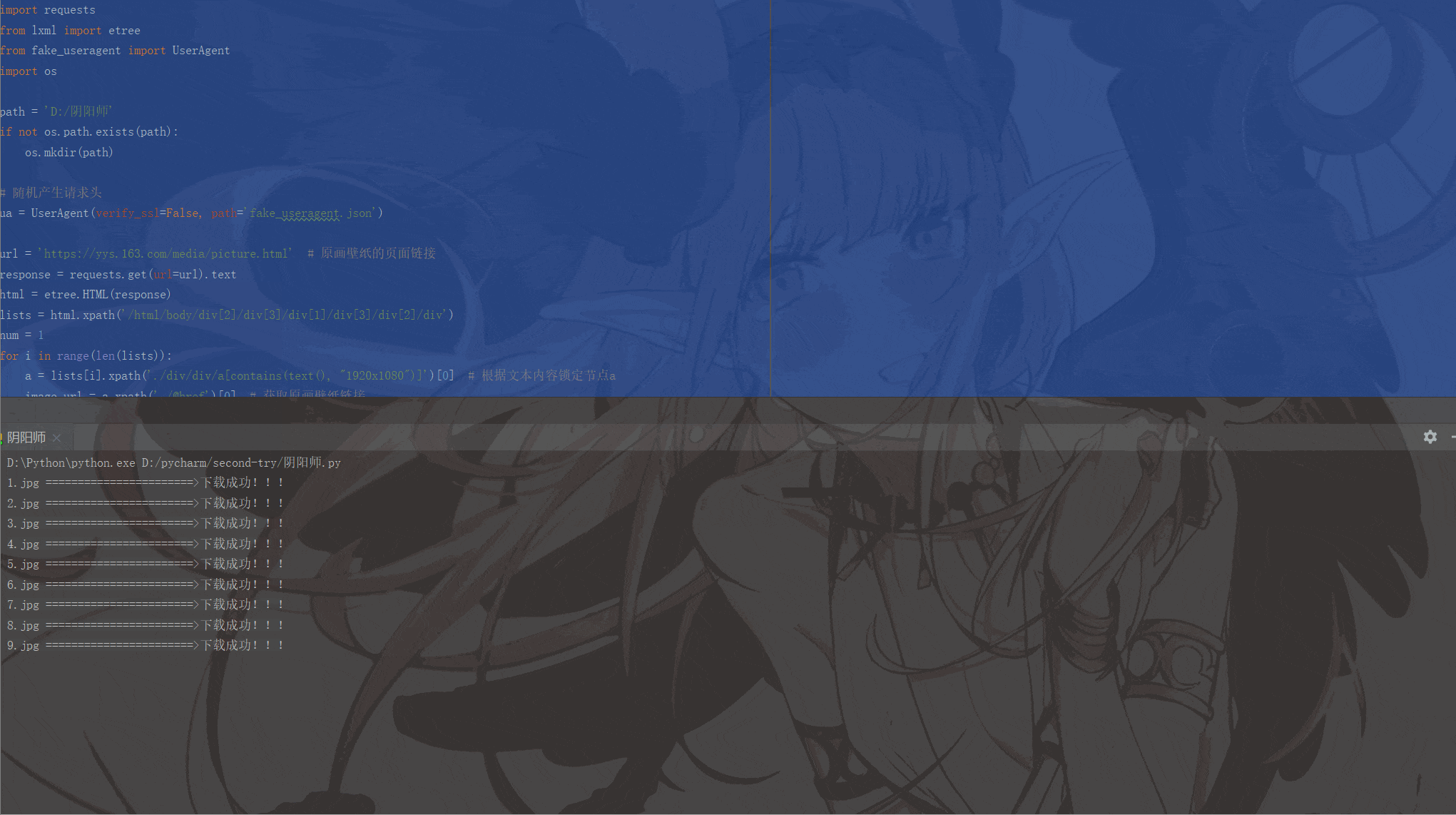
print(image_name, '=======================>下载成功!!!')
f.close()
num += 1
|
运行结果如下:

四、合成视频
通过合成视频,可以慢慢欣赏爬取下来的原画,舒服极了。
代码如下:
1 2 3 4 5 6 | import cv2import os# 输出视频的保存路径video_dir = 'D:/yinyangshi/result.mp4'# 帧率fps = 0.2# 图片尺寸img_size = (1920, 1080)fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # opencv3.0 mp4会有警告但可以播放videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size)img_files = os.listdir('D:/yinyangshi/')for i in range(1, 397):
img_path = 'D:/yinyangshi/tupian/' + '{}.jpg'.format(i)
frame = cv2.imread(img_path)
frame = cv2.resize(frame, img_size) # 生成视频 图片尺寸和设定尺寸相同
videoWriter.write(frame) # 写进视频里
print(f'======== 按照视频顺序第{i}张图片合进视频 ========')videoWriter.release() # 释放资源
|
注意:合成视频时,图片的保存路径和视频的生成路径不能包含中文!!!
阴阳师原画合集
相关免费学习推荐:python教程(视频)
以上就是Python简单地实现一键提取阴阳师原画方法的详细内容,更多文章请关注木庄网络博客!!
相关阅读 >>
Python面向对象是什么?分析Python面向对象实例来解密
excel文件读取的两种方式
Python中关于模块查找的使用详解
Python 编程开发 实用经验和技巧大放送
关于Python如何操作消息队列(rabbitmq)的方法教程
Python如何安装urllib2库
Python中两种方法实现模拟登陆的代码实例
Python除了爬虫还可以做什么
Python注释怎么写
Python中x[::]什么意思
更多相关阅读请进入《Python》频道 >>

人民邮电出版社
python入门书籍,非常畅销,超高好评,python官方公认好书。
转载请注明出处:木庄网络博客 » Python简单地实现一键提取阴阳师原画方法




