本文摘自php中文网,作者little bottle,侵删。
本篇文章主要讲述了用scrapy实现新浪微博爬虫,具有一定的参考价值,感兴趣的朋友可以了解一下 ,看完不妨自己去试试哦!
最近因为做毕设的原因,需要采集一批数据。本着自己动手的原则,从新浪微博上采集到近百位大家耳熟能详的明星14-18年的微博内容。看看大佬们平常都在微博上都有哪些动态吧~
1.首先项目采用scrapy编写,省时省力谁用谁知道。
采集的网站为weibo.com,是微博的网页端。稍稍麻烦了一点,但相对于移动段和wap站点来说内容稍微更全一点。
2.采集之前我们先来看下微博都给我们设置了哪些障碍。
- 登录
- 页面js渲染
由于微博对于没登录的用户默认都是302跳转到登录界面,所以采集微博钱必须得让微博认为,本次采集偷了个懒,直接是先手动登录然后保存cookie到scrapy上,请求的时候带上cookie去访问,因为采集量并不是很大,估计也就10w条左右。这里需要对刚入scrapy的小伙伴需要提醒一下,scrapy的cookie是类似与json的形式,不像平常在requests上直接粘贴就可以用,需要转换一下格式。
大概就是像这样,所以需要把登录后的cookie粘贴出来用代码转换一下,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
应该来说一个cookie差不多够用,我这我保存的是三个cookie,多个cookie简单的办法是把多个cookie直接放在一个数组里面,每次请求的时候用random函数随机挑一个出来,当然这只是针对采一批数据就撤的情况,大规模必须维护一个账号池。请求的时候带上ua,和cookie。如下:
微博是以oid区分每个用户的,我们以吴彦祖微博为例,在微博搜索界面搜索吴彦祖,进入主页右键查看网页源代码我们可以看到:
此处的oid即是每个用户的唯一标识。对应用户的主页地址即为https://weibo.com + oid,
有了地址,我们直接进入微博界面进行采集即可,拼凑出url地址,例如:
https://weibo.com/wuyanzu?is_all=1&stat_date=201712#feedtop
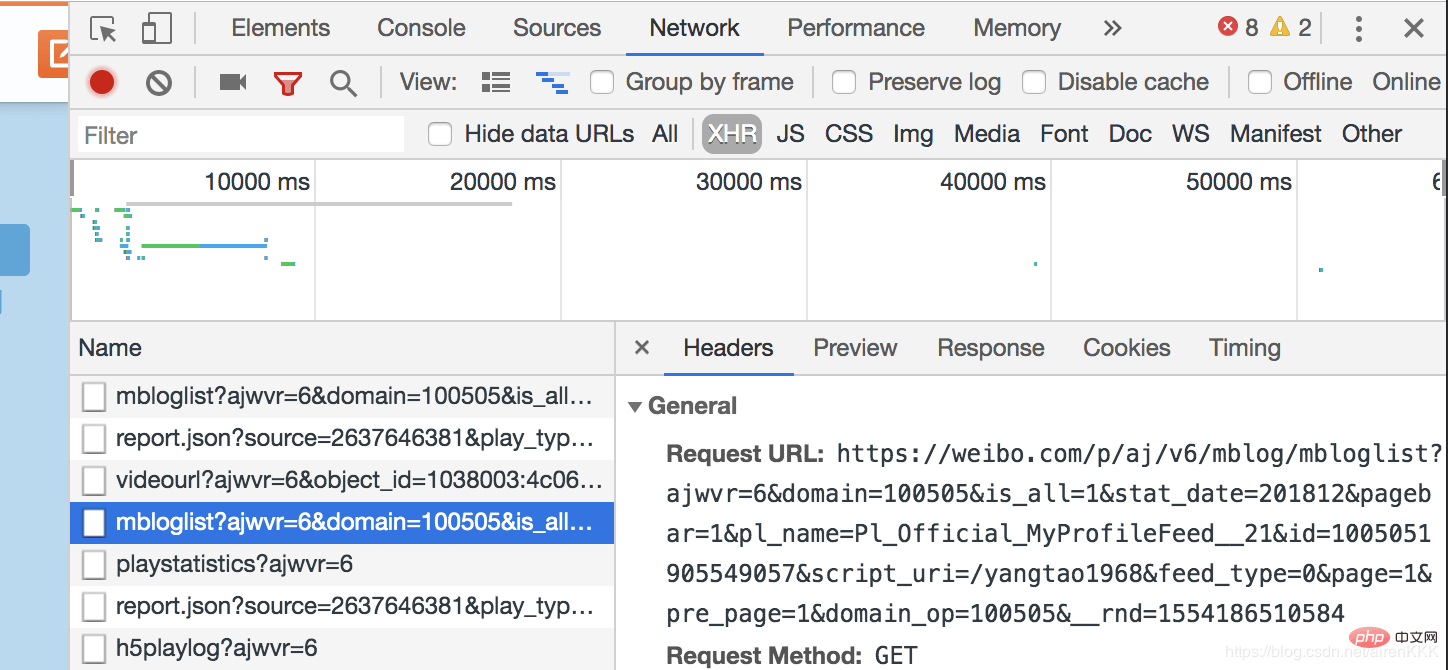
这是吴彦祖2017年12月份的微博,我们不难发现,只需改变stat_date后面的数字即为对应微博地址。对于某些微博量比较多的用户,月份的微博可能还涉及到js再加载一次,当然,我们高冷的男神吴彦祖先生肯定是不会发那么多的,我们再找一个微博量比较大的自媒体,例如:
可以看到,余下的微博是需要通过js异步加载来呈现给用户的。打开浏览器开发者模式,
相关阅读 >>
web自动化测试(二)selenium 3启动ie, firefox,chrome代码示例
更多相关阅读请进入《Python》频道 >>

Python编程 从入门到实践 第2版
python入门书籍,非常畅销,超高好评,python官方公认好书。




