本文摘自php中文网,作者不言,侵删。
本篇文章给大家带来的内容是关于Python的序列化和反序列化模块的简单介绍(实例代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。序列化:将对象转换为可通过网络传输或可存储到本地磁盘的数据格式的转换过程,称为序列化,反之,称为反序列化
json: 用来实现不同语言,不同程序直接的信息交互,json支持所有高级语言之间的序列化交互,json只能通过 字典—>字符串—>字典 的格式转换
注:json是读写序列化格式
pickle: python 中独有的序列化方法,如果有需要Python可以把Python中几乎所有的类型都可以序列化转换
注:pickle是二进制读写序列化格式
json与pickle都有相同的方法:
x.dumps():将得到的json或pickle数据序列化为一个bytes,然后将这个bytes写入磁盘或进行传输
x.loads():把得到的json或pickle数据从磁盘中读到内存中时,把内容先读到一个bytes中,然后再用loads反序列化出对象
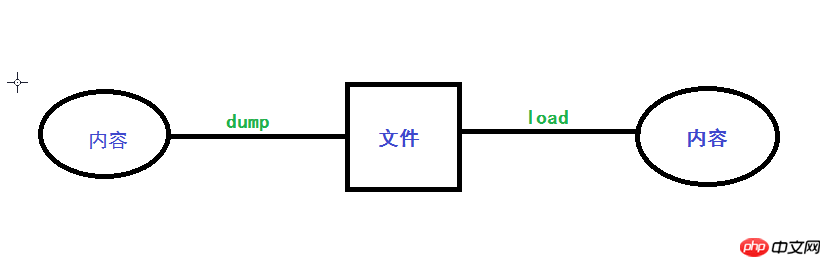
x.dump():可直接将得到的json或pickle数据序列化后保存到文件中
x.load():可直接读取文件中的json或pickle数据进行反序列化
实例:
序列化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
反序列化
1 2 3 4 5 6 7 8 9 |
|
相关推荐:
python3序列化与反序列化用法实例
序列化和反序列化的详细介绍
以上就是Python的序列化和反序列化模块的简单介绍(实例代码)的详细内容,更多文章请关注木庄网络博客!!
相关阅读 >>
更多相关阅读请进入《Python》频道 >>

Python编程 从入门到实践 第2版
python入门书籍,非常畅销,超高好评,python官方公认好书。




