本文摘自php中文网,作者小云云,侵删。
本文主要介绍了Python实现简单网页图片抓取完整代码实例,具有一定借鉴价值,需要的朋友可以参考下。利用python抓取网络图片的步骤是:
1、根据给定的网址获取网页源代码
2、利用正则表达式把源代码中的图片地址过滤出来
3、根据过滤出来的图片地址下载网络图片
以下是比较简单的一个抓取某一个百度贴吧网页的图片的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
进一步对代码进行了整理,在本地创建了一个“图片”文件夹来保存图片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
|
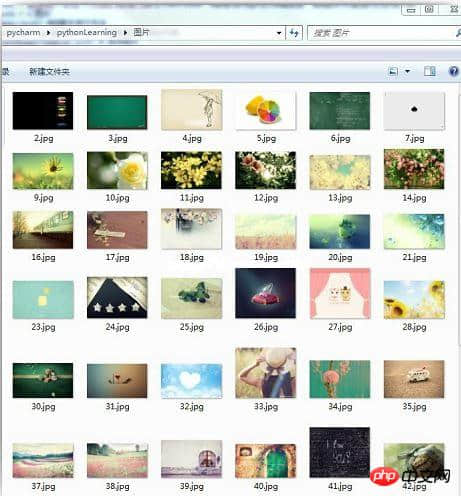
结果在“图片”文件夹下保存了几十张图片,如截图:
相关推荐:
PHP简单网页图片抓取类
如何把这里的图片抓取到本地
PHP+Ajax远程图片抓取器下载的例子
以上就是实例详解Python实现简单网页图片抓取的详细内容,更多文章请关注木庄网络博客!!
相关阅读 >>
更多相关阅读请进入《Python》频道 >>

Python编程 从入门到实践 第2版
python入门书籍,非常畅销,超高好评,python官方公认好书。




