本文摘自php中文网,作者巴扎黑,侵删。
最近刚接触python,找点小任务来练练手,希望自己在实践中不断的锻炼自己解决问题的能力。这个小爬虫来自慕课网的一门课程,我在这里记录的是自己学习的过程中遇到的问题和解决方法以及爬虫之外的思考。这次的小任务就是写一个小爬虫。为啥选这个来练手呢,最最重要的原因就是大数据太热了,就像武汉的现在的天气。数据之于”大数据“,就好比武器之于战士,砖瓦之于高楼。没有了数据,”大数据“就是空中阁楼,根本没法落地,应用于实际。数据怎么来呢?两种途径,一个是自取,一个他取。自取不必多说,另外一种就是他取,这个“他”就是指的互联网。
首先要明白爬虫:一种按照一定的规则,自动地抓取万维网信息的程序或者脚本(来自百度百科)。顾名思义,那就是要访问页面,然后将页面中的内容保存下来,然后从保存下来的页面中筛选出你感兴趣的内容,再把它另外存放起来。实际生活中,这种事我们经常干:我们在一个无聊的下午,在浏览器里输入一段地址进行页面访问,然后遇到感兴趣的文章或者段落,选中它,然后复制粘贴到一个word文档里。如果我们把以上对一个页面做的事,变成对成百万上千万的页面也这样做,那你的数据就会越来越大,我们把这个过程称之为“数据采集”。
爬虫的优势就在于:自动化,批量化。这里就会有一个误会,在我还没接触爬虫之前,我以为爬虫可以爬取我“看不到”的东西,后来才明白爬虫是用来爬取我“看不完”的东西。
下面是这个爬虫的架构和爬行流程
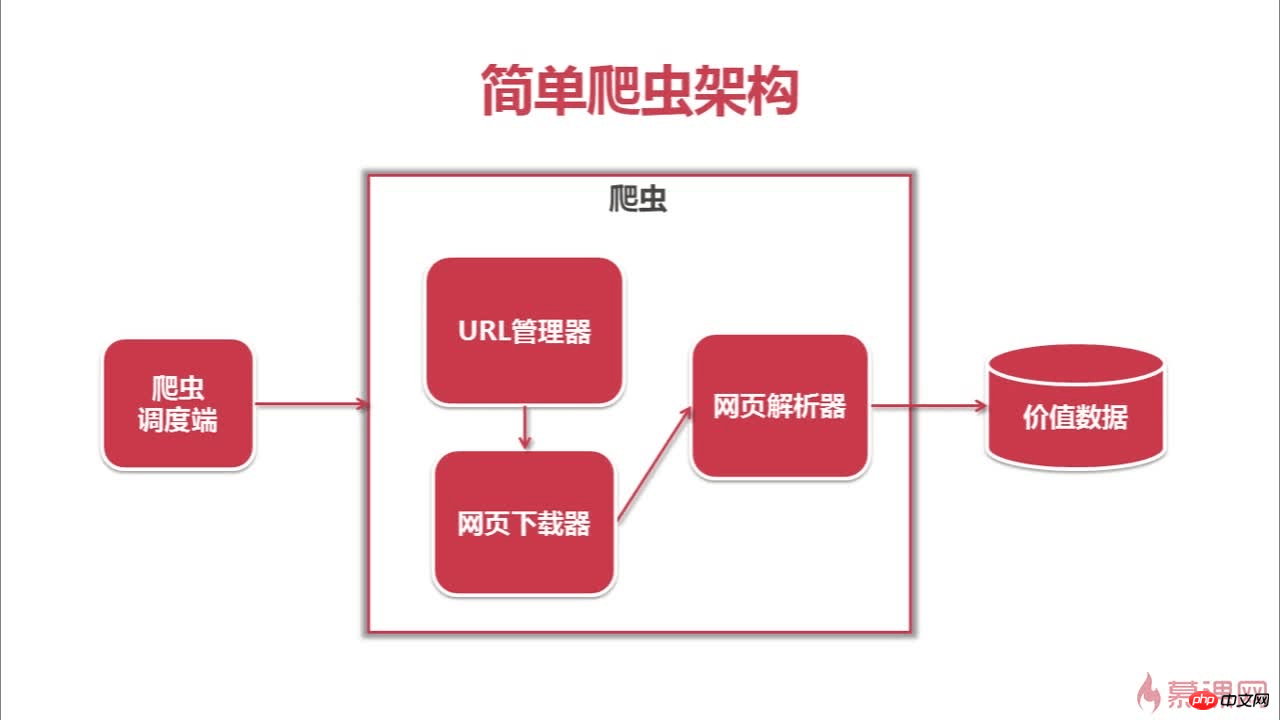
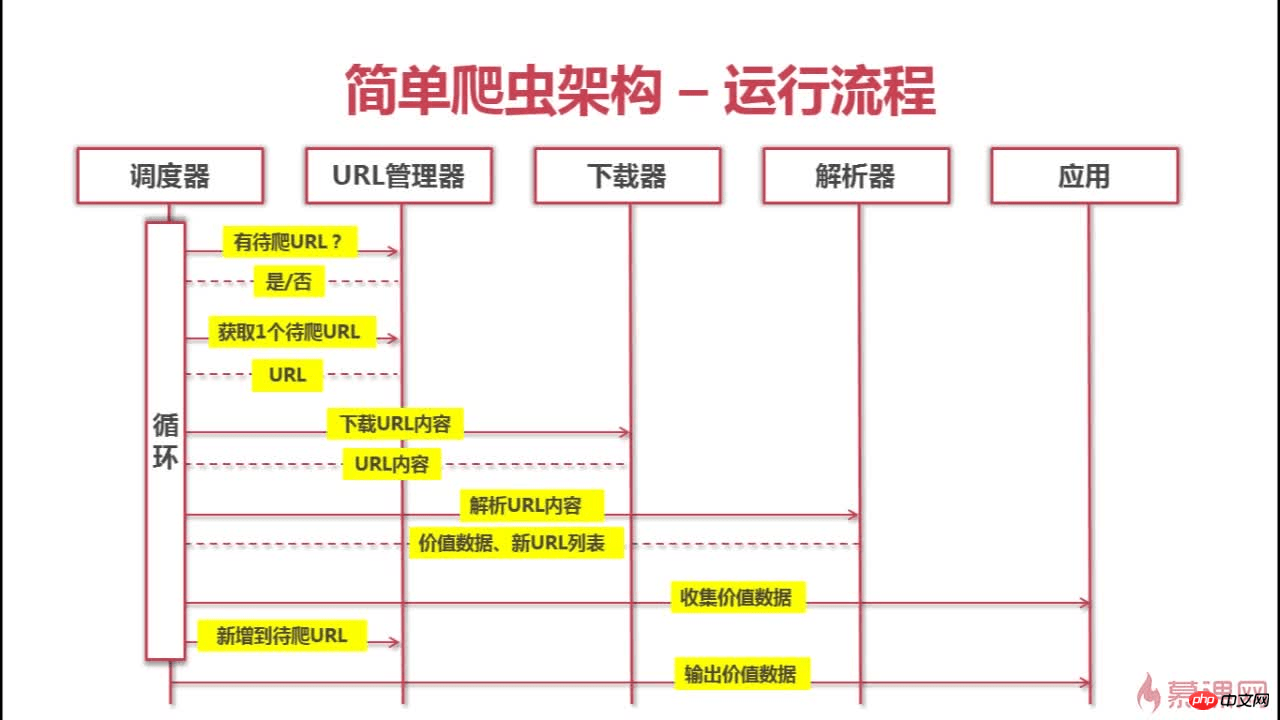
以上就是爬虫&问题解决&思考的详细内容,更多文章请关注木庄网络博客!!
相关阅读 >>
更多相关阅读请进入《Python》频道 >>

Python编程 从入门到实践 第2版
python入门书籍,非常畅销,超高好评,python官方公认好书。




