本文摘自雷锋网,原文链接:https://www.leiphone.com/category/academic/EdmCMrJKTf6KnZ09.html,侵删。

在 Yann Lecun 等人的推动下,自监督学习成为了深度学习领域最受瞩目的技术之一。互联网世界源源不断产生的数据流无疑是充分发挥自监督学习能力的最佳土壤。然而,将自监督学习应用于自然场景将面临哪些严峻的挑战?且看来自 CMU 的 Abhinav Gupta 团队如何对此展开研究。
自监督学习旨在消除表示学习对人工标注的需求,我们希望自监督学习利用自然场景下的数据学习表征,即不需要有限的和静态的数据集。真正的自监督算法应该能够利用互联网上产生的连续数据流,或者利用智能体在探索其环境时产生的数据流。
但是传统的自监督学习方法在这种情况下有效吗?在本文中,我们通过实验对「连续自监督学习」问题展开了研究。在自然场景下学习时,我们希望使用连续(无限)的非独立同分布数据流,它遵循视觉概念的非平稳分布。我们的目标是在不遗忘过去看到的概念的条件下,学习一种鲁棒、自适应的表征。
本文指出,直接将现有的方法应用于这种连续学习的设定存在以下问题:(1)计算效率低下、数据利用率低(2)在一些流数据源中,时间相关性(数据非独立同分布)导致表征较差(3)在具有非平稳数据分布的数据源上进行训练时,展现出灾难性遗忘的迹象。我们作者提出使用回放缓冲区(replay buffer)来缓解低效和时间相关性问题。我们进一步提出了一种新的方法,通过保留最少的冗余样本来增强回放缓冲区。最小冗余(MinRed)缓冲区让我们即使是在由单个具身智能体获得的序列化视觉数据组成的最具挑战性的流场景中,也可以学习到有效的表征,并缓解利用非平稳语义分布的数据学习时的灾难性遗忘问题。
计算机视觉领域正经历着从「监督学习」到「自监督学习」的范式转换。在自监督学习场景下,由于我们不再受制于手动数据标注的成本,可以释放数据的真正潜能。近年来,一些工作开始将现有的方法拓展到包含超过 10 亿张图片的超大规模数据集上,从而希望学习到更好的表征。那么,我们是否准备好在自然场景下部署自监督学习,从而利用无限的数据的全部潜力呢?
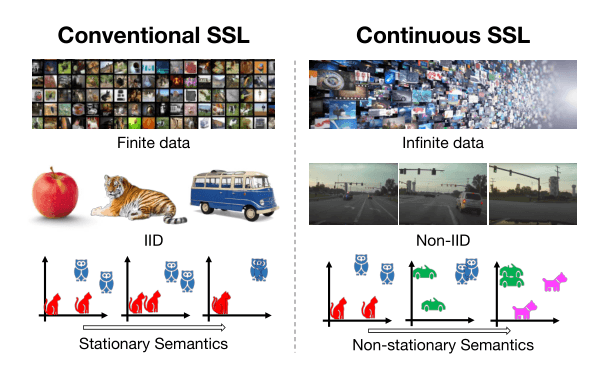
图注:传统自监督学习与持续自监督学习对比。传统自监督学习设定下,数据集是固定的。而自然场景下持续收集到的数据是无限、非独立同分布、具有非平稳语义的。因此,传统设定很难作为自然场景下部署的自监督学习的对比基准。
尽管自监督学习有望利用互联网或机器人智能体生成的无限数据流,但当下的自监督学习方法仍然依赖于传统的数据集设置。我们采用积累的图像和视频创建训练语料库,然后利用数百个经过打乱的数据遍历优化模型。使用数据集的主要是为了复现基准测试。然而,这种传统的静态学习设置适用于作为自监督学习的基准测试吗?这种设置是否准确地反映了在自然场景下部署的自监督系统所面临的挑战?
答案是否定的。例如,考虑一个这样的自监督的系统,它试图学习网络多年积累下来的汽车的表征。目前的实验设定只评估静态学习,而不评估模型在不忘记旧车型的情况下适应新车型的表征的能力。此外,部署的机器人自监督学习智能体主动地从输入的视频中获取帧数据。由于时间是连贯的,这些数据具有很强的结构性和相关性。然而,由于现有的自监督基准测试依赖于通过随机抽样产生独立同分布样本的数据集,它们并没有反映这一挑战。
在本文中,我们超脱于数据驱动的自监督学习,进而研究现有的持续自监督学习方法的性能。具体而言,我们探讨了两种部署的方法面临的挑战:(1)基于互联网的自监督模型,依赖于持续获得的图像/视频数据;(2)基于智能体的自监督系统,直接根据智能体传感器数据学习。以上两种方式都依赖于持续生成新数据的流数据源,为自监督学习基准测试带来了以下三个独特的挑战:
(1)存储无限数量的数据是不可行的。由于带宽或传感器速度的限制,在自然场景下获取数据通常要耗费一定时间。因此,我们不可能进行逐 Epoch 的训练。传统的自监督学习方式每次使用一个样本,学习器的效率较低,经常需要等待可用的数据,未充分利用处理的数据。一些研究人员依靠回放缓冲区从训练过程中解耦出数据采集工作。那么,在采集数据同时使表征持续提升的情况下,回放机制有多大的效果?
(2)不能「打乱」流数据源从而创建独立同分布样本的 mini-batch。相反,样本的顺序是由数据源本身决定的。训练数据不一定满足独立同分布要求,这对传统的表示学习方法带来了挑战。那么,如何让现有的自监督方法,从而在各种非独立同分布条件下学习到鲁棒的表征?
(3)真实世界的数据是非平稳的。例如,在世界杯期间,人们会看到更多与足球相关的图片。此外,探索室内环境的机器人会观察到根据时间聚类的语义分布。智能的终身学习系统应该能够不断地学习新概念,同时不忘记来自非平稳数据分布的旧概念。然而,经验表明,传统的对比学习方法可以使表征对当前的布过拟合,产生遗忘现象。那么,我们应该如何设计可以在非平稳条件下学习的自监督学习方法?
本文的主要贡献包括:确定了在持续自监督学习设定下出现的三个关键挑战——即训练效率、对非独立同分布数据流的鲁棒性和非平稳语义分布下的学习。我们都构建了针对性的数据流来模拟每项挑战,定量地展示了现有自监督学习方法的缺点,提出了这些问题的初步解决方案。我们探索了缓冲自监督学习(Buffered SSL)的思想,它用回放缓冲区来增强现有的方法,以提高训练效率。其次,我们通过去除存储样本的相关性,提出了一种新方法来处理非独立同分布数据流。我们说明了,在非平稳数据分布下,去相关缓冲可以防止遗忘,并改善持续学习。
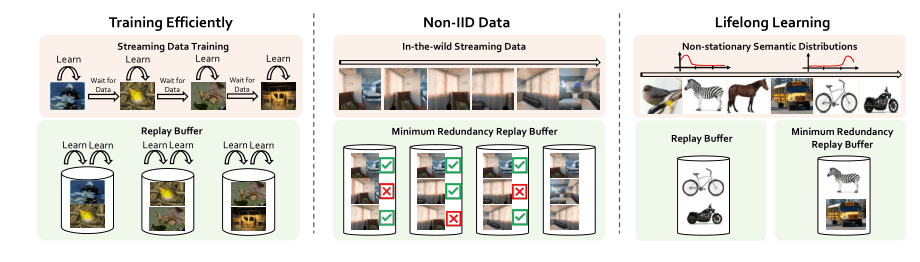
图注:在自然场景下部署持续自监督学习系统面临的三大挑战。
首先,无线数据流中的样本无法重复,我们使用回放缓冲区增强现有的自监督学习方法,显著缓解了该问题。其次,持续从自然场景下收集的数据往往在时间上是相关的,不满足优化算法的独立同分布假设。我们通过增强回放缓冲区来保留最低限度的冗余样本(MinRed),从而生成相关性较低的数据。最后,在自然场景下收集到数据的于一分部是非平稳的,模型可能会「遗忘」在过去的分布中看到的概念。MinRed 缓冲区可以通过从各种语义类中收集独特的样本缓解「遗忘」问题。
3 流自监督学习 v.s 传统自监督学习
现有的自监督学习方法依赖于固定大小的数据集。这些数据集是有限、不可变、现成可用的。因此,我们可以对样本进行编号、打乱其顺序,在训练的所有节点上都可以获取样本。传统的自监督学习通过在数据集上进行多个 Epoch 的训练来利用这些特性的优势。
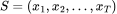
相较之下,持续自监督学习依赖于流数据源 S,即无标签传感器数据的时间序列,该序列的长度可能是无限的。在给定的任意时间点 t 上,从流数据源 S 中抓取数据会产生当前的样本,此时无法获取未来的样本。只有在过去抓取时保存下来的样本才能被再次访问。
在持续自监督学习设定下,数据加载时间和执行每个优化步所需的时间之比是很重要的参数。在大多数情况下,由于数据架子速度较慢、传感器帧率较低,即使使用并行化技术,优化算法仍然需要等待数据加载。因此,持续自监督学习方法需要在使用流数据源中获得的样本进行训练的情况下,高效、持续地构建更好的表征。
4 持续自监督学习有何优势? 扩增独特图像的数量是否有助于表示学习?
为了理解增长训练数据的规模的作用,我们为所有在 2008 年至 2021 年间上传至图片分享网站 Flickr.com 的带有知识共享标签的图像赋予编号。接着,我们使用该编号创建了各种规模的数据集,通过多伦传统自监督学习方法训练视觉表征。我们采用了代表性的对比学习方法 SimSiam,它通过优化增强不变性损失来学习表征:
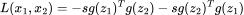
其中,和是对于图像的两种随机变化,为模型输出的表征,sg 为停止梯度,g 为预测头。
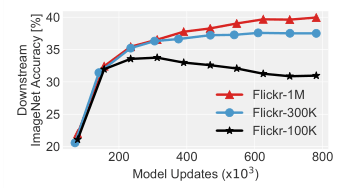
图注:使用 ResNet-18 主干网络在不同规模的数据集上训练的 SimSiam 模型在 ImageNet 分类下游任务中的准确率。
如上图所示,使用更多元化的数据训练可以得到更好的表征,说明扩展独特图像的规模是有利的,而持续自监督学习可以将这一特性发挥到极致。
5 持续自监督学习面临的挑战
在持续自监督学习设定下学习表征带来了一些传统自监督学习方法不存在挑战:
(1)多轮训练 vs 单趟训练。在使用流数据源时,我们无法重新访问没有储存的过去获得的样本。流数据的长度可能是无限的,将完整的流数据存储下来并不可行,连续自监督方法需要通过在样本上「单趟」训练的方式学习表征。
(2)采样效率。由于传感器帧频或带宽的限制,在现实世界中从流数据源中采样可能十分低效。由于优化算法可能在等待数据时处于空闲状态,学习表征所需的时间会显著增加。
(3)相关样本。许多自然场景下的流数据源存在时间相关性。例如,来自在线视频或机器人探索环境的连续帧会展现出微小的变化。这种相关性打破了传统优化算法所依赖的独立同分布假设。
(4)终身学习。使用无限的数据流让我们可能不断改进视觉表征。然而,自然场景下非平稳的数据流会导致自监督学习方法很快遗忘不再与当前分布相关的特征。随着我们不断获取新数据,持续自监督学习方法如何在不遗忘之前学到的概念的情况下将新概念集成到表征中?
上述挑战同时存在于自然场景下,直接评估当前的自监督学习方法会使我们无法全面、单独地分析每一项挑战。因此,我们通过设计一组分别突出各项挑战的数据流,评估其对现有自监督学习方法的影响。
计算效率和数据效率是目前阻碍自监督学习在自然场景下的连续数据流上部署的两大挑战。对于大多数实际应用来说,可能很高,因此自监督学习方法应该更好地利用空闲时间来改进模型。其次,获取新样本的成本仍然很高。简单地将现有的自监督学习方法部署到流数据设定下会在使用一次后就丢弃每批数据。然而,目前的深度学习优化实践表明,在多个 epoch 中迭代地训练相同的样本有助于学习到更好的表征。
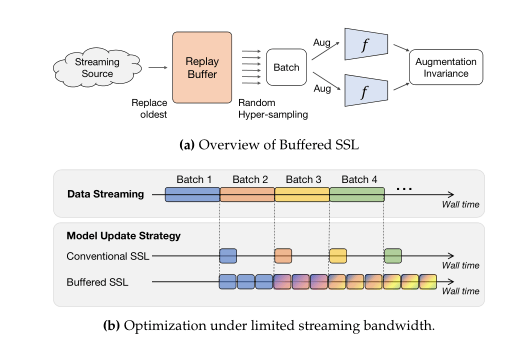
图注:缓冲自监督学习引入了回放缓冲区,使模型即使在有限的带宽设定下仍然能持续训练。
为了在流数据设定下提升数据效率,我们维护了一个固定大小的回放缓冲区,存储少量最近的样本。这个想法的灵感来自常被用于强化学习和监督持续学习的经验回放技术。如上图(a)所示,回放缓冲区将流数据源与训练过程解耦。当流数据可用时,可以将其添加到回放缓冲区,替换加入缓冲区时间最早的样本(即先进先出的队列更新规则)。同时,通过对缓冲区随机采样,可以随时生成训练数据的 batch。如上图(b)所示,回放缓冲区让我们可以在空闲等待期间继续训练。回放缓冲区让我们可以通过多次采样来重用样本,从而减少总的数据成本。
我们研究了回放缓冲区在使用单趟训练数据时的作用。我们使用 Flickr 数据集中序号为前 2 千万的图像,分别训练了使用/不使用回放缓冲区的 ResNet-18 SimSiam 模型。
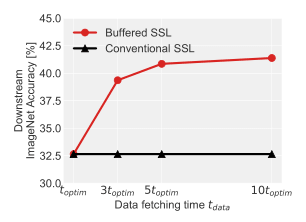
图注:具有带宽限制的流自监督学习。缓冲自监督学习可以利用空闲时间有效地改进学习到的表征
如上图所示,通过维护一个小的回放缓冲区(只包含最近的 64,000 张图像),缓冲自监督学习能够充分利用空闲时间。与传统自监督学习方法相比,显著改进了表征。回放缓冲区还可以提高持续自监督学习设定下的数据效率,每个样本都可以被多次重用。数据利用率与超采样率 K 成正比,K 是为训练生成的 mini-batch 数与从流数据源获取的 mini-batch 数之比。
为了理解超采样的限制,我们训练将一个带有回放缓冲区的 ResNet-18 SimSiam 模型训练了固定的更新次数。
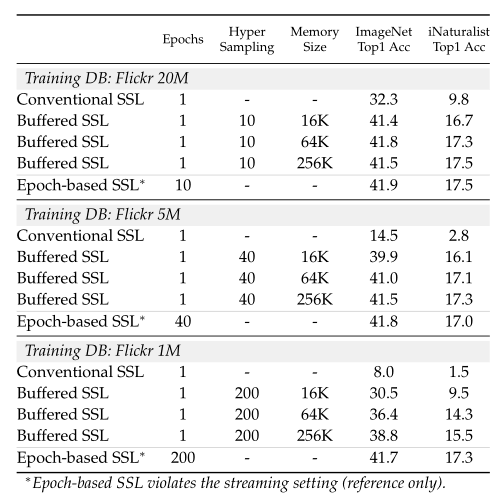
图注:数据效率。通过回放缓冲区增强自监督学习方法可以提升数据效率,使我们可以单次训练数据流。
如上图所示,基于 Epoch 的自监督学习和缓冲自监督学习在优化更新次数相同的情况下,缓冲自监督学习的性能更佳。尽管需要利用单趟数据进行训练,超采样率为 K=10 的缓冲自监督学习可以获得与基于 epoch 的训练相当的性能(即使缓冲区的大小仅为 64,000 张图像)。随着超采样率提升,回放缓冲区变得越来越重要。例如,当 K=200 时,无论缓冲区大小如何,在数量相同的数据上,缓冲自监督学习仍然相较于传统自监督学习有显著的提升。然而,随着缓冲区大小提升,学习到的表征也会更好。因此,在高度超采样时,缓冲区被来自流数据源的新图像缓慢更新,增大缓冲区的大小可以防止模型快速过拟合缓冲区中的样本。
自然场景下得到的视觉数据往往是相关、非独立同分布的。这与传统自监督学习方法使用的数据形成了鲜明的对比。例如,ImageNet 数据集使我们可以从 1,000 个均匀分布的对象类别中对图像采样。即使是在更大的数据集上训练的方法,也不太可能在 mini-batch 中遇到高度相关的样本。但是,即使是在静态图像设定下,持续自监督学习设定下的持续数据流也往往不满足上述假设。
令为一个样本序列,其中从大数据集中随机采样生成,这种采样近似于独立同分布。因此,样本和样本之间高度相关的概率较低。样本相关说明图像在视觉上十分相似,或即使视觉上不相似但描述了相似的语义内容。然而,在持续自监督学习设定下,独立同分布假设往往不被满足,即。假设持续的数据流中的连续样本具有相同的相关性概率,长度为 b 的 batch 中随机数据对相关似然很大:
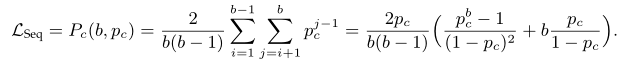
在引入尺寸为的回放缓冲区时,相关似然越低,则表征学习更有效。
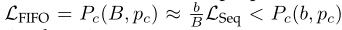
尽管回放缓冲区可以减小相关性似然,但需要非常大的回放缓冲区,才能在样本高度相关的设定下得到较低的。为了缓解这一问题,我们提出了一种修正后的回放缓冲区——最小冗余回放缓冲区(MinRed),它只保留去相关的样本,因此可以主动地降低。
为此,我们基于学习到的嵌入空间确定冗余样本。假设一个回放缓冲区的最大容量为 B,它已经包含了 B 个具有表征的样本。为了向该缓冲区中加入新的样本 x,我们根据所有样本对之间的余弦距离丢弃大多数冗余的样本:
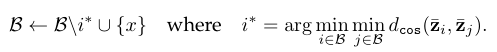
换而言之,我们丢弃那些与其最近邻具有最小余弦距离的样本。
非独立同分布数据流上的实验
我们评估了自监方法在两种具有高度时间相关性的数据流上的性能。第一个数据流是通过连接 Kinetics 数据集中的视频样本创建的。我们从每个视频中随机采样帧,并将它们依次添加到数据流中。第二个训练流是 KrishnaCAM 数据集中的连续帧,记录了一名计算机视觉研究生九个月的以自我为中心的视频。我们分别在每个流数据上训练传统的 SimSiam、听过回放缓冲区增强的缓冲 SimSiam,通过 MinRed 缓冲区增强的 SimSiam。
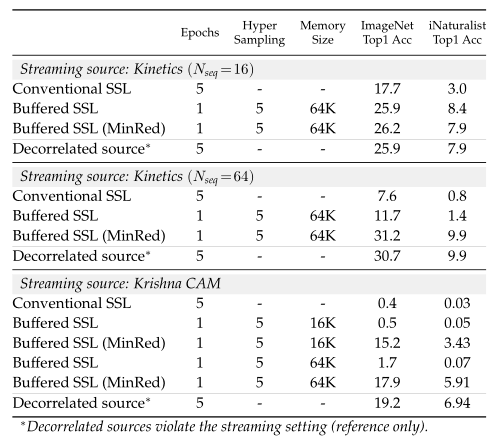
图注:视觉上相关的自监督学习。在具有高度时间相关性的数据源上训练的缓冲和非缓冲 SimSiam 表征的线性分类效果。MinRed 通过对数据进行解相关学到更好的表征。
如上图所示,数据的相关性严重扰乱了传统模型的训练,而常规的回放缓冲区技术在一定程度上缓解了这个问题,但学习到的表征在高度相关的数据流(例如,的 Kinetics 数据集和 KrishaCAM 数据集)上仍然会收到影响。相较之下,本文提出的 MinRed 缓冲在上述设定下表现出了显著的性能提升。使用 MinRed 缓冲区训练的模型性能往往十分接近使用完全解相关的数据流训练。
训练样本的相关性:生成具有较低相关似然的训练样本是缓冲自监督学习的优势之一,因此这些样本更加接近独立同分布。

图注:使用/不使用回放缓冲训练时的 batch 内的数据相关性。
如上图所示,MinRed 回放缓冲区中的内容比 FIFO 缓冲区中内容的相关性明显较低。在使用 KrishnaCAM 数据集时,MinRed 缓冲区能够维护过去更长的时间内的独特帧。在使用 Kinetics 数据集时,MinRed 缓冲区用可以产生包含更多独特视频中的帧构成的训练用 mini-batch。
在探索世界时,我们会遇到各种目标类的分布,会经常遇到一些未曾见过的类别,语义类的分布通常会实时偶然变化。然而,传统的自监督学习方法针对有限的概念学习,这些概念被重复使用了数千次。这种简化的学习设定不能反映概念在自然场景下的非平稳特性。
用于自监督学习对比基准的非平稳数据流

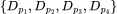
受监督式持续学习的启发,我们引入了具有平滑偏移语义分布的设置。首先,我们基于 Wordnet 的类别层次结构将 ImageNet-21K 数据集划分为 4 份,每一份包含语义相似的类别的图像。对于每一类,我们拿出 25 张图像用于评估。我们通过从打乱的上述 4 个数据集中依次随机采样图像并汇总,从而得到训练数据流。其中,是的排列。这样一来,我们就模拟了语义分布的平滑变化。我们旨在学习到可以在不发生过拟合、不遗忘先前看到的概念的情况下,能够判别所有数据集中概念的表征。
我们分别在单趟数据流上使用传统的 SimSiam、带有回放缓冲区的 SimSiam、带有最小冗余缓冲区的 SimSiam 进行训练。在评估阶段,我们利用学到的表征训练了一个线性分类器,用来识别 ImageNet-21K 数据集中的所有类别,并在每个的留出集上评估了模型准确率,实验结果取三次排列的平均值。
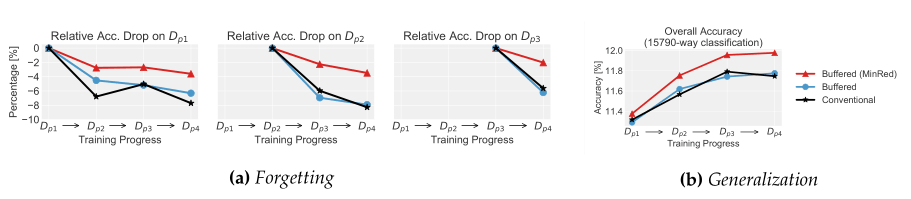
图注:完整 ImageNet 数据集上的持续无监督表征学习实验结果。(a)在每个任务的数据上训练,测量在其它每个任务上的准确率下降情况。最小冗余缓冲区可以保留先前任务的实例,因此缓解了传统自监督学习中的灾难性遗忘问题,能够有规律地回放缓冲区中的内容。(b)15,790 个类别上的整体准确率。通过确保来自过去类别分布的图像没有被遗忘,最小冗余缓冲区可以学习更好的总体表征。
如上图所示,所有的方法性能都会受到「遗忘」现象的损害。然而,MinRed 缓冲区维护了语义范围更广的训练数据,使用了 MinRed 缓冲区的 SimSiam 的性能下降较小,始终具有较好的泛化能力。
在本文中,作者指出了构建鲁棒、可部署的自监督学习器所面临的三大挑战。通过利用回放缓冲区重新访问较早访问过的样本,作者提升持续自监督学习模型的效率。未来,研发通过预先评估样本价值实现快速拒绝样本的方法可能会提高数据效率。作者还提出了新的最小冗余缓冲区技术,该技术可以丢弃相关性较强的样本,使我们能够模拟独立同分布训练数据的生成。此外,未来的研究可以更加关注利用数据流的相关性,从细粒度的差异中学习表征。
在具有非平稳语义分布的数据流中,作者发现 MinRed 缓冲区缓解了灾难性遗忘的问题,它们能够维护来自过去分布的独特样本。然而,当引入新概念时,作者观察到「饱和泛化」的现象,这可能是由于:(1)余弦衰减学习率(2)模型的容量是固定的,无法学习大的新概念序列。作者发现,使用恒定的学习率进行训练并不能显著提高模型性能。作者还发现,定期扩展模型架构并不会带来明显的性能提升。我们需要以自监督的方式不断学习新的概念。

雷峰网(公众号:雷峰网)
相关阅读 >>
持续发力游戏产业 netflix再收购游戏工作室boss fight
35mm高定光学努比亚z50s pro正式发布 售价3699
梦幻西游花花世界掏空盲僧钱包,这把武器居然可以拜师“少林寺”
更多相关阅读请进入《新闻资讯》频道 >>




