本文摘自雷锋网,原文地址:https://www.leiphone.com/news/202004/DX9Si2cN6yT6Czpf.html,侵删。
一份标准的出台,便是一个技术发展前景的指明灯。
今年3月份,联邦学习IEEE标准草案完成并通过标准工作组表决,预计年中将正式出台。这预示着首份中国企业牵头推动的IEEE联邦学习国际标准即将落地;同时也意味着联邦学习提出三年之后,其在解决数据孤岛和保护用户隐私方面的作用已得到国际认可。
作为一种人工智能协同技术,联邦学习标准的出台对接下来的AI落地也将有着举足轻重的意义。这一标准从提出到表决出台,这中间发生了什么?这样一个国内企业主导的标准范式,对中国有哪些具体的意义?
数据联盟:技术标准发起的原因

联邦学习这项大规模分布式学习人工智能技术, 简单来说,即一种数据不出本地,就可完成机器学习多方协作建立模型的技术。其应用领域可以分为: 1) 用于保护用户隐私的,面向个人消费者市场的场景; 2) 同时面向个人客户和企业或者政务部门的业务场景。
微众银行和谷歌分别在不同方向领导着研究的重心,同时微众银行等中国企业引领了大部分的技术创新, 业界标准制定及应用市场。
谷歌于2016年利用联邦学习解决安卓手机终端用户在本地更新模型的问题,也即能够基于本地小数据进行不断机器学习训练。而联邦学习在国内兴起的主要原因却是:这种数据不出本地的联合建模技术,正是解决国内企业数据孤岛现状的“良药”。
例如,在医疗领域,每个医院都有不少患者健康状况的信息,由于隐私保护等问题,医院之间的数据不能够取长补短。如何克服医院之间的这种数据孤岛问题?
让机器学习在尊重隐私保护的前提下集成各方数据进行训练。显然,能够让参与方在数据不出本地的基础上联合建模的联邦学习给予了答案。
也就是说,它对To C端((消费者))有吸引力,对于To B端(企业)则更有吸引力。这从联邦学习的中文名字变化也可以看出。在早期国内将「Federated Learning」大多翻译为「联合学习」,现多称为「联邦学习」。
其中的区别是,如果用户是个人,确实是把他们的模型「联合」起来学习;而如果用户是企业、银行、医院等大数据拥有者,这种技术则更像是将诸多「城邦」结合起来,「联邦」一词则更为准确。
这一名字的变化,也反映着联邦学习的研究主体从理论转向实际应用的变化趋势。那么数据如何联合?如何使用?如何激励更多的成员参与进来?
显然,需要有一个标准来评判大家应用体系的好坏。既然是标准,能够有权威的国际标准组织背书当然更有公信力。于是一触即燃,2018年底由微众银行等企业带头向IEEE标准协会递交了联邦学习关于联邦学习架构和应用规范的标准P3652.1。
2018年12月,IEEE标准协会批准这一标准的立项。
2019 年2月份,由微众银行杨强教授担任工作组主席的IEEEP3652.1(联邦学习基础架构与应用)标准工作组第一次开启,参会人数30余位。这次会议也是联邦学习历史上的首次会议,会上确定了联邦学习标准的基本框架。
4个月后,标准工作组的第二次会议在美国洛杉矶开启,这次会议成员增添了Eduworks、doc.ai等国外企业。在会上,各工作组成员梳理并添加了各自领域内的联邦学习典型案例。
第三次标准工作组会议是在澳门召开,不同于前两次,这次会议重点聚焦联邦学习各项指标的评估如何量化。值得一提的是,这次是在 IJCAI 2019 大会上,与之相伴而生的还有联邦学习国际研讨会的第一次召开,标志着联邦学习有了国际社区,“联邦学习er”有了专门讨论学习的地方。
第四次会议开始于11月份,着重对联邦学习的安全测评与评级进行规划,细化了联邦学习在To B(企业端)、To C(用户端)以及To G(政府端)不同情境下的场景分类。其中, 微众银行,腾讯云,京东,华为,中国电信,小米,华大基因,中电科大数据, Eduworks等企业机构, 分别贡献了联邦学习在金融,市场营销,城市交通,通讯与设备,医疗,教育及政府服务等方面的应用场景。
而第五次会议是采取了线上的方式,共有三十余家海内外头部企业与研究机构共同参与,反复而细致的讨论之后,也完成了标准草案的撰写。目前正提交IEEE标准协会(StandardAssociation, SA)投票表决。五次标准工作会议,历时一年多,期间辗转多地,即使遇疫情也没有落下进度。
一项标准的成文涉及细节非常多,其中定义、概念、分类、算法框架规范、使用模式和使用规范等都需要反复斟酌。不仅涉及到技术范式,如何在不同的场景下激励各方积极参与的激励机制也非常重要。
正如微众银行人工智能首席科学家范力欣博士在接受AI 科技评论采访时候谈到:“每个人的贡献都不容忽视,虽然在讨论过程中,大家讨论很激烈,但是都希望标准更加完善,更加成体系,最后也达成了很好的结果”。所以,联邦学习标准的“成文”,集成了“各家所长”,也是一次“联邦学习”的过程。

(雷锋网(公众号:雷锋网))
联邦学习标准的制定不仅影响生产力,更多的是影响生产关系。联邦学习标准具体内容包括两部分:一是技术体系,涉及如何在保护隐私的前提下,通过引入各方数据的参与来提高模型性能, 二是激励机制,涉及如何通过分配公平合理的回馈给数据贡献方, 来吸引更多的数据拥有方参与联邦学习的联盟。
简而言之, 提高模型性能,无疑是提高了生产力。而激励机制,则定义了数字经济中的生产关系。具体来说, 激励机制多采用经济学原理和博弈论知识,其中理性人假设,尝试对各个参与方定性,根据其利益最大化的“性格”,激励让更多的人参与。帕累托最优标准评判利益分配方式是否符合各方博弈最优解。通过不损失其他人利益同时增加系统中某些人利益的标准,让各个参与方“心服口服”。
而“利益标准”不是唯一的衡量指标,对于联邦学习来说,一个好的体系必须考虑到社会效益。将政府行为纳入评价、激励机制,在考虑个体效益的同时,平衡社会福利,借力福利经济学的内容促进社会生产关系,提升社会福利的同时让参与方承担相应的社会责任。
所以,联邦学习标准的激励机制一方面让更多人参与,另一方面, 也协调优化了参与方的利益关系,提升了整体的经济效益及社会福利。由微众银行牵头,海内外多家企业和研究机构合作参与制定的联邦学习IEEE标准,与其他诸多国际标准的不同之处在于, 国外企业并没有在标准的制定和决策中占据主导地位。恰恰相反, 本着公平、公正、公开原则制定的联邦学习标准, 吸引了众多中国头部和中小企业的积极参与.
而会随着该标准在国际上的广泛应用, 中国企业的影响力也会逐步外溢, 并提升中国企业在全球化环境中的话语权。
正如范力欣博士所谈到的那样:“微众银行之所以能够领导联邦学习的标准制定,除了杨强教授的个人学术魅力外,更重要的是在于微众银行所倡导的公平、公正、公开的联邦学习技术开源平台, 能够吸引更多的国内外机构参与。”
标准的好坏,重点还在于能否让大家去遵守。
联邦学习的国际标准是由中国企业牵头发起,国外企业和研究机构对联邦学习标准的认识和接受会滞后一些。比如, 谷歌因为其本身只是面向C端,在自身数据充足的情况下,暂时没有意识到B端业务应用的巨大前景, 也就没有加入到标准制定的行列中。
但如Intel,IBM等国外企业都已积极参与到联邦学习标准化的讨论中来。进一步来看,与Facebook、谷歌、苹果这些有“数据垄断”意味的企业合作,让其接受一项对大小企业都一视同仁的技术标准,这显然是也是标准发起的愿景之一。另一方面,联邦学习的安全性, 也是该标准重点规范的一个方面。
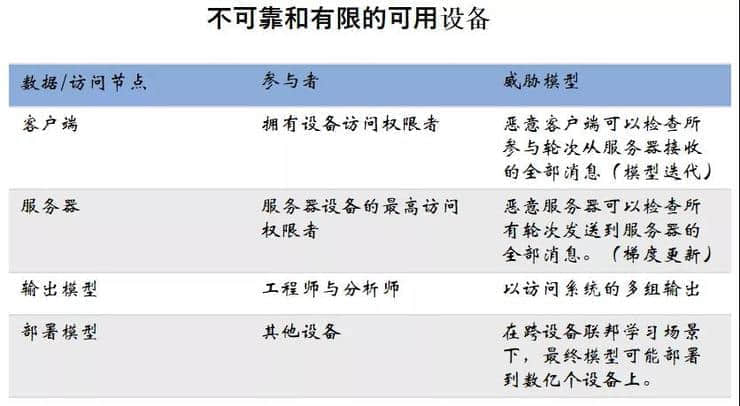
对于存在个别参与方不诚实或者欺诈的行为, 联邦学习标准不仅仅是从技术上检测/预防这些恶意行为, 而且通过设计激励机制来从动机上杜绝恶意行为。更加系统的后续配套工作如何推进?
范力欣博士谈到:“有三个方向,第一个是国内的行业推广,让更多的国内有相关应用的企业首先加入行列;其次是面向国外,欧洲因为有GDPR法规的颁布,对数据隐私保护更加规范,所以国际标准的推广,会对欧洲重点关注; 最后是吸纳更多To B、To C、To G的案例,让测评体系更加完善”。
打铁还需自身硬,标准制定公平、公开、公正的同时,吸纳更多应用案例,增强标准公信力,才能让更多企业加入进来。
雷锋网原创文章,未经授权禁止转载。详情见转载须知。
相关阅读 >>
更多相关阅读请进入《IEEE》频道 >>




