为使 FF 专注表征形状图像的长期相关性,我们需要创建具有不同长期相关性、但非常相似的短期相关性的负数据,这可以通过创建一个包含相当大的 1 和 0 区域的掩码来完成。之后通过将一个数字图像与掩码相加,为负数据创建混合图像和一个不同的数字图像来乘以掩码的反面(图 1)。
通过随机位图开始创建蒙版,在水平和垂直方向上使用[1/4, 1/2, 1/4]形式的过滤器重复模糊图像,经反复模糊的图像阈值设为 0.5。在使用四个隐藏层(每个隐藏层包含 2000 个 ReLU)训练 100 个 epochs 后,若使用最后三个隐藏层的归一化活动向量作为 softmax 输入,可得到测试误差为1.37%。
此外,不使用完全连接层、而使用局部接受域(没有权重共享)可以提高性能,训练 60 个 epochs 的测试误差为 1.16%,该架构使用的 "对等归一化"可防止任何隐藏单元极度活跃或永久关闭。
监督学习 FF 算法
在不使用任何标签信息的情况下学习隐藏表征,对最终可能够执行各种任务的大模型来说非常明智:无监督学习提取了一大堆特征供各任务使用。但如果只对单任务感兴趣,并想使用一个小模型,那么监督学习会更适合。
监督学习中使用 FF 的一种方法是在输入中包含标签,正数据由具有正确标签的图像组成,而负数据由具有错误标签的图像组成,标签是二者间的唯一区别,FF 会忽略图像中与标签不相关的所有特征。
MNIST 图像中包含有黑色边框,可减轻卷积神经网络的工作压力。当使用标签的 N 个表征中的一个来替换前 10 个像素时,第一个隐藏层学习内容也会轻易显现。一个有 4 隐藏层的网络中,每个隐藏层包含 2000 个 ReLU,层与层之间的完全连接在 60 个 epochs 后,经 MNIST 其测试误差为 1.36%,反向传播要达到该测试性能需要大约 20 个 epochs。将 FF 学习率加倍并训练 40 个 epochs,可得到稍差的测试误差,为 1.46% 。
使用 FF 训练后,通过从包含测试数字和由 10 个 0.1 条目组成的中性标签的输入开始,由网络进行一次前向传递来对测试数字进行分类,之后,除第一个隐藏层外,其他所有隐藏活动用作在训练期间学习的 softmax 输入,这是一种快速次优的图像分类方法。最好的方式是使用特定标签作为输入的一部分来运行网络,并积累除第一个隐藏层以外的所有层的优点,在分别对每个标签执行此操作后,选择具有最高累积优度的标签。在训练过程中,来自中性标签的前向传递被用于挑选硬负标签,这使得训练需要约⅓ 的 epochs 。
通过每个方向将图像抖动最多的两个像素用于增加训练数据,从而为每个图像获得 25 种不同的偏移,当中使用了像素空间布局的知识,使其不再是排列不变的。这种用增强数据训练同个网络 500 个 epochs,测试误差可达到 0.64%,类似于用反向传播训练的卷积神经网络。如图 2,我们也在第一个隐藏层中得到了有趣的局部域。

图 2:在抖动 MNIST 上训练的网络第一个隐藏层中 100 个神经元的局部域,类标签显示在每张图像前 10 个像素中
使用 FF 模拟自上而下的感知效应
目前,所有图像分类案例都使用了一次学习一层的前馈神经网络,这意味着在后面层中学到的东西不会影响前面层的学习。这与反向传播相比似乎是个主要弱点,克服这种明显限制的关键是,将静态图像视为相当无聊的视频,由多层递归神经网络处理。
FF 对正数据和负数据都在时间上向前运行,但每层活动向量由上一层和下一层在前一个 time-steps 的归一化活动向量确定(图 3)。对这种方法是否有效进行初步检查,可以使用由静态 MNIST 图像组成的“视频”输入,该图像在每个时间帧中简单重复,底层是像素图像,顶层是数字类的 N 个表征之一,有两个或三个中间层,每层有 2000 个神经元。
在初步实验中,循环网络运行了 10 个 time-steps,每个 time-steps 的偶数层根据奇数层的标准化活动进行更新,奇数层根据新的标准化活动更新,其交替更新旨在避免双相振荡,但目前似乎并不需要:在有一点阻尼的情况下,基于前一个 time-steps 归一化状态,所有隐藏层的同步更新学习效果略好,这对不规则架构而言是有益的。因此,该处实验使用了同步更新,新的预归一化状态被设置为上个预归一化状态的 0.3 ,加上了计算新状态的 0.7。
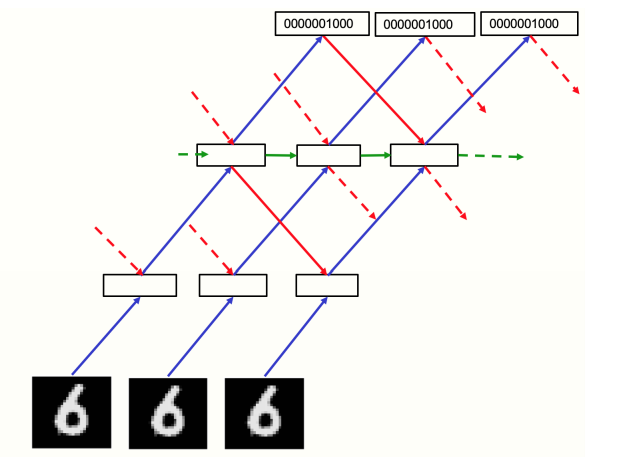
图 3:用于处理视频的循环网络
如图 3,网络在 MNIST 上训练 60 个 epochs,对每个图像的隐藏层通过一次自下而上传递进行初始化。
此后,网络运行 8 次带有阻尼的同步迭代,通过对 10 个标签中的每个标签运行 8 次迭代,并选择在第 3 到 5 次迭代中平均优度最高的标签来评估网络的测试数据性能,测试误差为 1.31%。负数据通过网络一次前向传递以获得所有类别的概率,根据概率按比例在不正确的类别间进行选择生成,从而提高训练效率。
使用空间上下文的预测
循环网络中,其目标是令正数据的上层输入和下层的输入间保持良好的一致性,而负数据的一致性不好。具有空间局部连通性的网络中具备一个理想的属性:自上而下的输入将由图像更大的区域决定,并且有更多处理阶段的结果,因此它可以被视为对图像的上下文预测,也即是基于图像局部域自下而上的输入所应产出的结果。
如果输入随时间变化,自上而下的输入会基于较旧的输入数据,因此必须学习预测自下而上输入的表征。当我们反转目标函数的符号,并针对正数据进行低平方活动,自上而下的输入应学会抵消正数据的自下而上输入,这样看来与预测编码十分相似。层规范化意味着即使取消工作得很好,大量信息也会被发送到下一层,如果所有预测误差都很小,则会被归一化放大。
使用上下文预测作为局部特征并提取教学信号学习的想法长期存在,但难点在于,如何在使用空间上下文、而非单侧时间上下文的神经网络中工作。使用自上而下和自下而上输入的共识作为自上而下和自下而上权重的教学信号,这种方法明显会导致崩溃,而使用其他图像的上下文预测来创建负数对的问题也没有完全解决。其中,使用负数据而不是任何负内部表征似乎是关键。
Hinton 接着在 CIFAR‑10 数据集上测试了 FF 算法的性能,证明了 FF 训练出的网络在性能上能够媲美反向传播。
该数据集有 50,000 张 32x32 的训练图像,每个像素具有三个颜色通道,因此,每个图像都有 3072 个维度。由于这些图像的背景复杂且高度可变,并且在训练数据很有限的情况下无法很好地建模,除非隐藏层非常小,否则包含两到三个隐藏层的全连接网络在使用反向传播进行训练时会严重过拟合,因此,目前几乎所有研究的结果都是针对卷积网络的。
反向传播和 FF 都是用权重衰减来减少过拟合,Hinton 对两种方法训练的网络性能进行了比较。对于 FF 训练的网络,测试方法是使用单个前向传播,或者让网络对图像和 10 个标签中的每一个运行 10 次迭代,并在第 4 到 6 次迭代中累积标签的能量(即当基于优度的错误最低时)。
结果,虽然 FF 的测试性能比反向传播差,但只稍微差了一点。同时,二者间的差距不会随着隐藏层的增加而增加。不过,反向传播可以更快地减少训练误差。
另外,在序列学习上,Hinton 也通过预测序列中下一个字符的任务证明了用 FF 训练的网络比反向传播更好。用 FF 训练的网络可以生成自己的负数据,更符合生物学。
Hinton 进一步将 FF 算法与其他已有的对比学习方法做了对比。他的结论是:
FF 是对玻尔兹曼机和简单的局部优度函数的结合;
FF 不需要反向传播来学习判别模型和生成模型,因此是 GAN 的一个特例;
在真实的神经网络中,与 SimCLR 这类自监督对比方法相比,FF 能够更好地衡量两种不同表示之间的一致性。
FF 吸收了玻尔兹曼机的对比学习
在 20 世纪 80 年代初期,深度神经网络有两种最被看好的学习方法,一个是反向传播,另一个便是做无监督对比学习的玻尔兹曼机(Boltzmann Machines)。
玻尔兹曼机是一个随机二元神经元网络,具有成对连接,在两个方向上具有相同的权重。当它在没有外部输入的情况下自由运行时,玻尔兹曼机通过将其设置为开启状态来重复更新每个二元神经元,其概率等于它从其他活动神经元接收到的总输入的逻辑。这个简单的更新过程最终从平衡分布中采样,其中每个全局配置(将二进制状态分配给所有神经元)具有与其负能量成比例的对数概率。负能量只是该配置中所有神经元对之间权重的总和。
玻尔兹曼机中的神经元子集是“可见的”,二进制数据向量通过将它们夹在可见神经元上呈现给网络,然后让它重复更新其余隐藏神经元的状态。玻尔兹曼机器学习的目的是使网络运行时可见神经元上二元向量的分布与数据分布自由匹配。
最令人惊讶的是,自由运行的玻尔兹曼机在热平衡时,可见神经元上显示的数据分布和模型分布之间的 Kullback-Liebler 散度具有一个非常简单的导数(对于任何权重):
相关阅读 >>
人工智能算法“照亮”月球永久阴影区 将助力阿尔忒弥斯计划确定登月点
更多相关阅读请进入《算法》频道 >>




