本文摘自雷锋网,原文链接:https://www.leiphone.com/category/academic/qsorv1nopg3Zse61.html,侵删。

作者 | 李梅、黄楠
过去十年,深度学习取得了惊人的胜利,用大量参数和数据做随机梯度下降的方法已经被证明是有效的。而梯度下降使用的通常是反向传播算法,所以一直以来,大脑是否遵循反向传播、是否有其它方式获得调整连接权重所需的梯度等问题都备受关注。
图灵奖得主、深度学习先驱 Geoffrey Hinton 作为反向传播的提出者之一,在近年来已经多次提出,反向传播并不能解释大脑的运作方式。相反,他正在提出一种新的神经网络学习方法——前向-前向算法(Forward‑Forward Algorithm,FF)。

与反向传播算法使用一个前向传递+一个反向传递不同,FF 算法包含两个前向传递,其中一个使用正(即真实)数据,另一个使用网络本身生成的负数据。
Hinton 认为,FF 算法的优点在于:它能更好地解释大脑的皮层学习,并且能以极低的功耗模拟硬件。
Hinton 提倡应放弃软硬件分离的计算机形态,未来的计算机应被设计为“非永生的”(mortal),从而大大节省计算资源,而 FF 算法正是能在这种硬件中高效运行的最佳学习方法。
这或许正是未来解决万亿参数级别的大模型算力掣肘的一个理想途径。
1 FF 算法比反向算法 更能解释大脑、更节能
在 FF 算法中,每一层都有自己的目标函数,即对正数据具有高优度,对负数据具有低优度。层中活动平方和可用作优度,此外还包括了诸多其他的可能性,例如减去活动平方和等。
如果可以及时分离正负传递,则负传递可以离线完成,正传递的学习也会更加简单,并且允许视频通过网络进行传输,而无需存储活动或终止传播导数。
Hinton 认为,FF 算法在两个方面优于反向传播:
一,FF 是解释大脑皮层学习的更优模型;
二,FF 更加低耗能,它使用极低功耗模拟硬件而不必求助于强化学习。
没有切实证据可以证明,皮层传播错误导数或存储神经活动是用于后续的反向传播。从一个皮层区域到视觉通路中较早的区域自上而下的连接,并不能反映出在视觉系统中使用反向传播时所预期的自下而上连接。相反,它们形成了循环,其中神经活动经过两个区域、大约六个皮层,然后回到它开始的地方。
作为学习序列的方式之一,通过时间的反向传播可信度并不高。为了在不频繁暂停的情况下处理感觉输入流,大脑需要通过感觉来处理的不同阶段传输数据,并且还需要一个可以即时学习的过程。管道后期表征可能会在后续时间里提供影响管道早期阶段表征的自上而下的信息,但感知系统需要实时进行推理和学习,而非停止进行反向传播。
这当中,反向传播的另一个严重限制在于,它需要完全了解前向传播执行的计算才能推出正确的导数。如果我们在前向传播中插入一个黑盒,除非学习黑盒的可微分模型,否则反向传播无法执行。
而黑盒不会对 FF 算法的学习过程造成影响,因为不需要通过它进行反向传播。
当没有完美的正向传播模型时,我们可以从多种强化学习方式中入手。其中的一个想法是,对权重或神经活动进行随机扰动,并将这些扰动与由此产生的收益函数变化相关联。但由于强化学习中存在高方差问题:当其他变量同时受到扰动时,很难看到扰动单个变量的效果。为此,要平均掉由所有其他扰动引起的噪声,学习率需要与被扰动的变量数量成反比,这就意味着强化学习的扩展性很差,无法与包含数百万或数十亿大型网络的反向传播竞争参数。
而 Hinton 的观点是,包含未知非线性的神经网络不需要求助于强化学习。
FF 算法在速度上可与反向传播相媲美,其优点是可以在前向计算精确细节未知的情况下进行使用,还可以在神经网络对顺序数据进行管道处理时进行学习,无需存储神经活动或终止传播误差导数。
不过,在功率受限的应用中,FF 算法还未能取代反向传播,比如对于在超大数据集上训练的超大模型,也还是以反向传播为主。
前向-前向算法是一种贪婪的多层学习程序,其灵感来自玻尔兹曼机和噪声对比估计。
用两个前向传播代替反向传播的前向+后向传播,两个前向传播在不同数据和相反目标上,以完全相同的方式彼此操作。其中,正向通道对真实数据进行操作,并调整权重以增加每个隐藏层的好感度,反向通道调整 "负数据 "权重以减少每个隐藏层的好感度。
本文探讨了两种不同的度量标准——神经活动的平方之和,以及负活动的平方之和。
假设某层的优度函数是该层中经过整流的线性神经元活动的平方和,学习目的是使其优度远高于真实数据的某个阈值、并远低于负数据的阈值。也即是说,在输入向量正确分类为正数据或负数据时,输入向量为正(即真实)的概率,可通过将逻辑函数 σ 应用于优度减去某个阈值 θ:
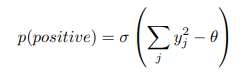
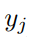
其中,是层归一化前隐藏单元 j 的活动。负数据可由神经网络自上而下连接进行预测,也可由外部提供。
使用逐层优化函数学习多层表示
很容易看出,可以通过使隐藏单元的活动平方和,对正数据高而对负数据低来学习单个隐藏层。但当第一个隐藏层活动被用作第二个隐藏层的输入时,仅需适用第一个隐藏层的活动矢量长度,即可区分正负数据,无需学习新的特征。
为防止这种情况,FF 在将隐藏向量长度作为下一层的输入前,会对其进行归一化,删除所有用于确定第一个隐藏层中的信息,从而迫使下个隐藏层使用第一个隐藏层中神经元的相对活动信息,该相对活动不受层规范化的影响。
也即是说,第一个隐藏层的活动向量具备一个长度和一个方向,长度用于定义该层的良性,只有方向被传递到下一层。
2 有关 FF 算法的实验
文中大部分实验使用了手写数字的 MNIST 数据集:50000 个用于训练,10000 个用于搜索良好超参数期间的验证,10000 张用于计算测试错误率。经设计后具有几个隐藏层的卷积神经网络可得约 0.6% 的测试误差。
在任务 "排列不变 "版本中,神经网络没有得到有关像素空间布局的信息,若训练开始前,所有训练和测试图像都受相同像素随机变异影响,那么神经网络的表现也会同样良好。
对于这个任务“排列不变”版本,带有几个全连接隐层的整流线性单元(ReLU)的前馈神经网络测试误差大约在 1.4%,其中大约需要20个 epochs 来训练。使用各种正则器如 dropout(降低训练速度)或标签平滑(加快训练速度),可将测试误差降至 1.1% 左右。此外,还可通过将标签的监督学习与无监督学习相结合来进一步降低测试误差。
在不使用复杂的正则化器的情况下,任务“排列不变”版本的测试误差为 1.4%,这表明了其学习过程与反向传播一样有效。
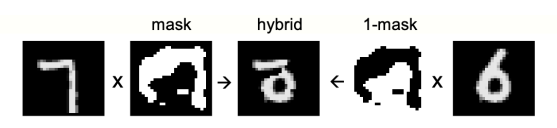
图1:用作负数据的混合图像
FF 有两个主要问题需要回答:如果有良好的负数据来源,它是否会学习有效的多层表示来捕获数据结构?负数据从何而来?
先使用手工负数据来回答第一个问题。将对比学习用于监督学习任务的常见方法是,在不使用任何有关标签信息的情况下,将输入向量转化为表示向量,学习将这些表示向量简单线性变换为使用的 logits 向量,在 softmax 中用来确定标签的概率分布。尽管具有明显的非线性,但这仍被称为线性分类器,当中 logits 向量的线性变换学习是有监督的,因不涉及学习任何隐藏层,无需导数的反向传播。FF 可通过使用真实数据向量作为正例、并使用损坏的数据向量作为负例来执行该表征学习。
相关阅读 >>
“雪绒星”点亮冬奥场馆,铝合金编织成雪花,每条曲线都来自算法
人工智能算法“照亮”月球永久阴影区,将助力阿尔忒弥斯计划确定登月点
史上首次,强化学习算法控制核聚变登nature:人造太阳向前一大步
更多相关阅读请进入《算法》频道 >>




