本文摘自php中文网,作者coldplay.xixi,侵删。

免费学习推荐:python视频教程
python爬取微博热搜存入Mysql
- 最终的效果
- 使用的库
- 目标分析
- 一:得到数据
- 二:链接数据库
- 总代码
最终的效果
废话不多少,直接上图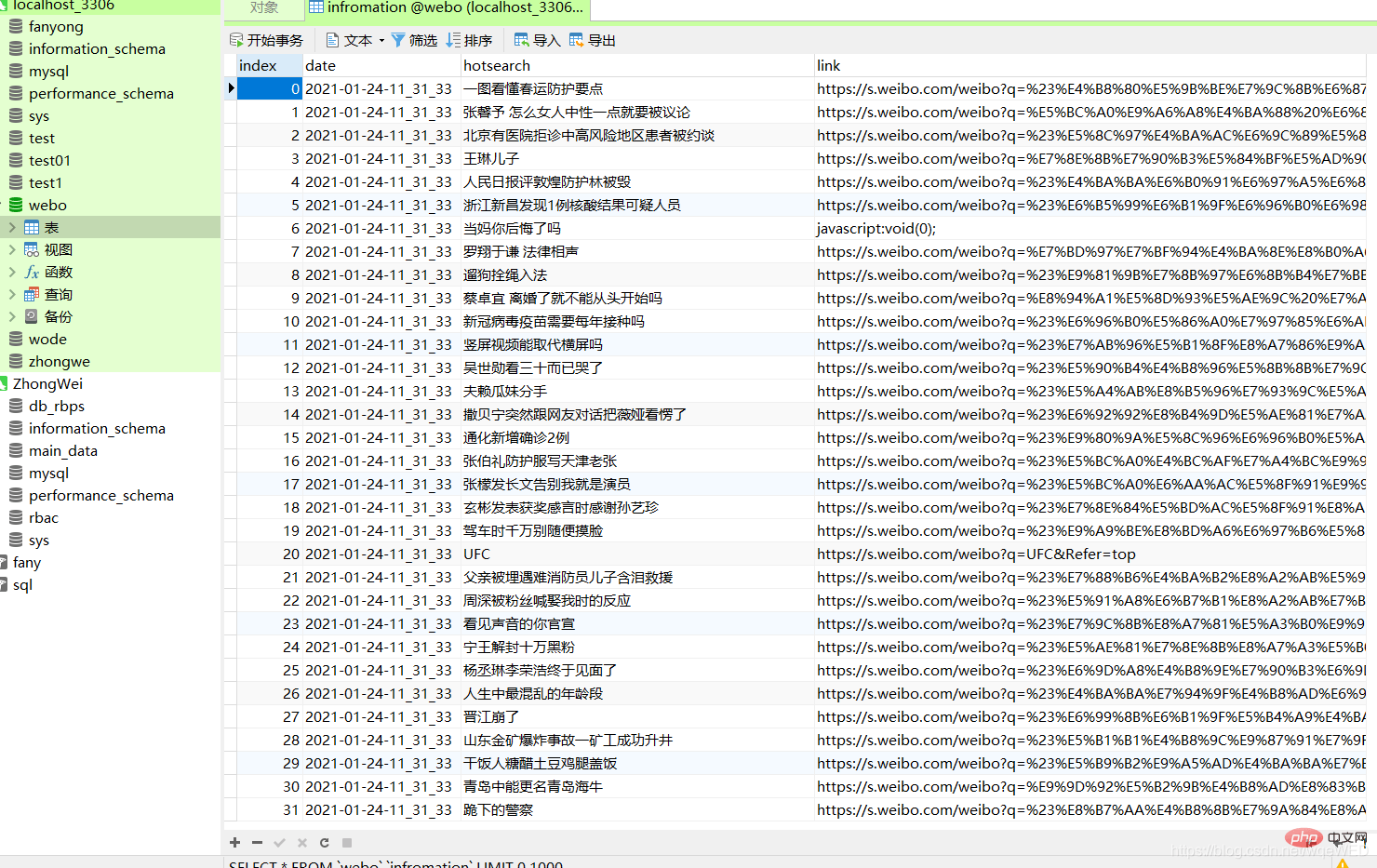
这里可以清楚的看到,数据库里包含了日期,内容,和网站link
下面我们来分析怎么实现
使用的库
1 2 3 4 5 |
|
目标分析
这是微博热搜的link:点我可以到目标网页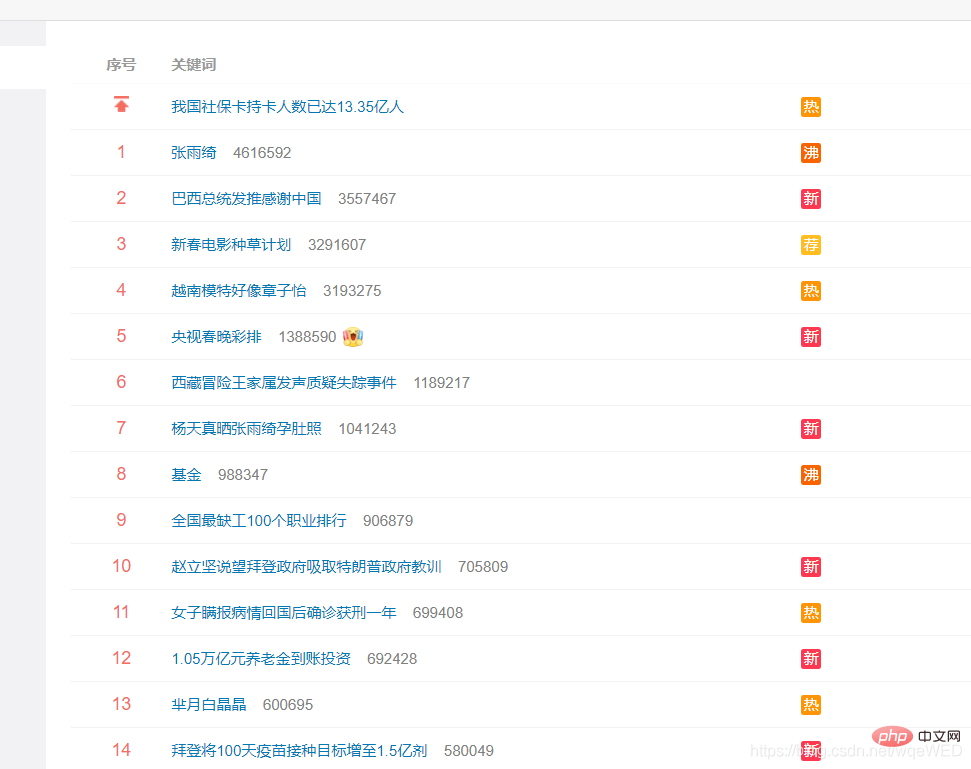
首先我们使用selenium对目标网页进行请求
然后我们使用xpath对网页元素进行定位,遍历获得所有数据
然后使用pandas生成一个Dataframe对像,直接存入数据库
一:得到数据
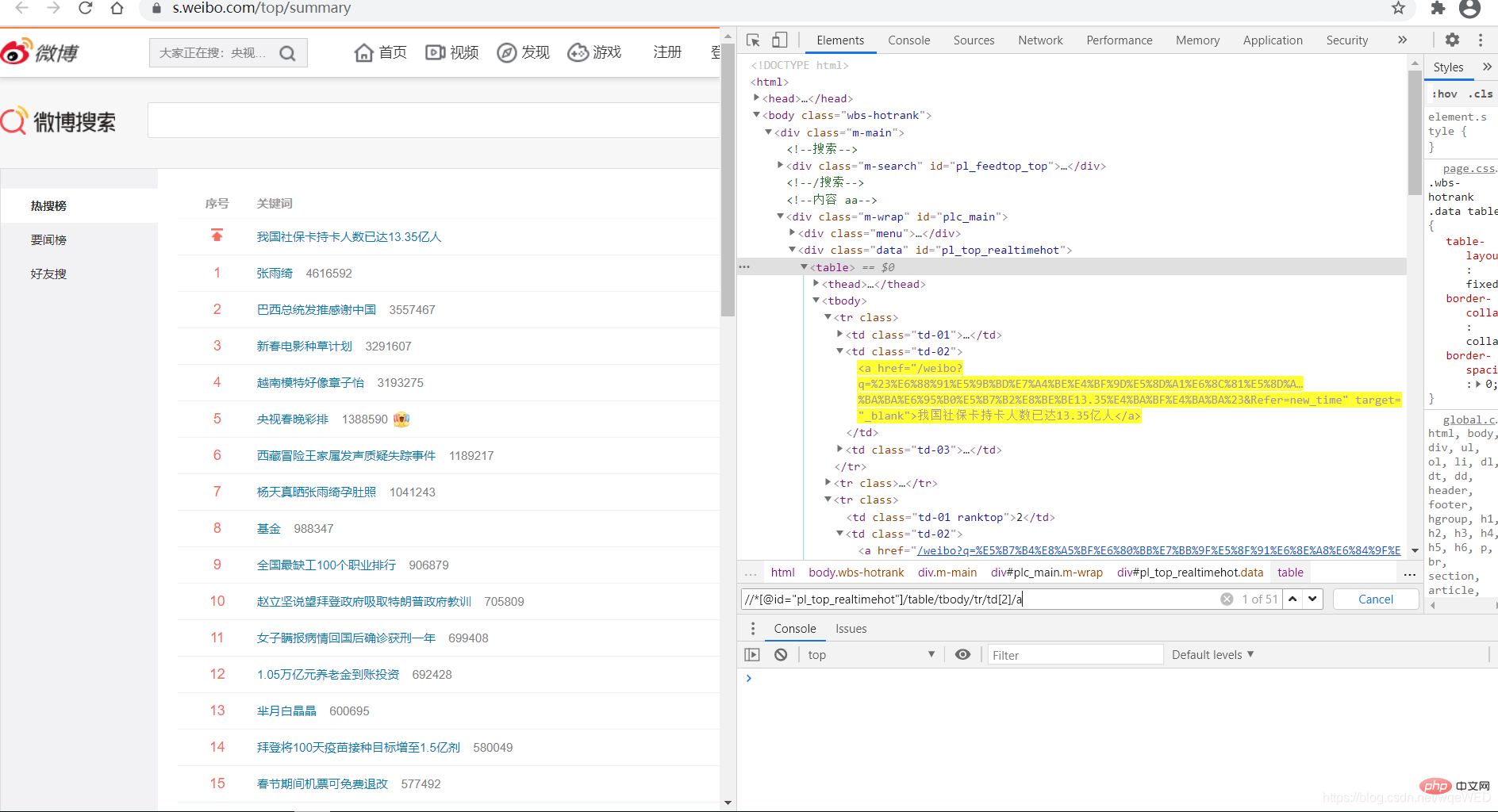
我们看到,使用xpath可以得到51条数据,这就是各热搜,从中我们可以拿到链接和标题内容
1 2 3 |
|
然后我们再使用zip函数,将date,context,links合并
zip函数是将几个列表合成一个列表,并且按index对分列表的数据合并成一个元组,这个可以生产pandas对象。
1 2 |
|
其中date可以使用time模块获得
二:链接数据库
这个很容易
1 2 |
|
总代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
希望能够帮到大家一点,大家一起共同进步,共同成长!
祝大家新年快乐!!!
相关免费学习推荐:python教程(视频)
以上就是python实现爬取微博热搜存入Mysql的详细内容,更多文章请关注木庄网络博客!!
相关阅读 >>
[译]the Python tutorial#input and output
更多相关阅读请进入《Python》频道 >>

Python编程 从入门到实践 第2版
python入门书籍,非常畅销,超高好评,python官方公认好书。




