本文摘自php中文网,作者不言,侵删。
这篇文章主要介绍了Python文本统计功能之西游记用字统计操作,结合实例形式分析了Python文本读取、遍历、统计等相关操作技巧,需要的朋友可以参考下本文实例讲述了Python文本统计功能之西游记用字统计操作。分享给大家供大家参考,具体如下:
一、数据
xyj.txt,《西游记》的文本,2.2MB
致敬吴承恩大师,4020行(段)
二、目标
统计《西游记》中:
1. 共出现了多少个不同的汉字;
2. 每个汉字出现了多少次;
3. 出现得最频繁的汉字有哪些。
三、涉及内容:
1. 读文件;
2. 字典的使用;
3. 字典的排序;
4. 写文件
四、效果
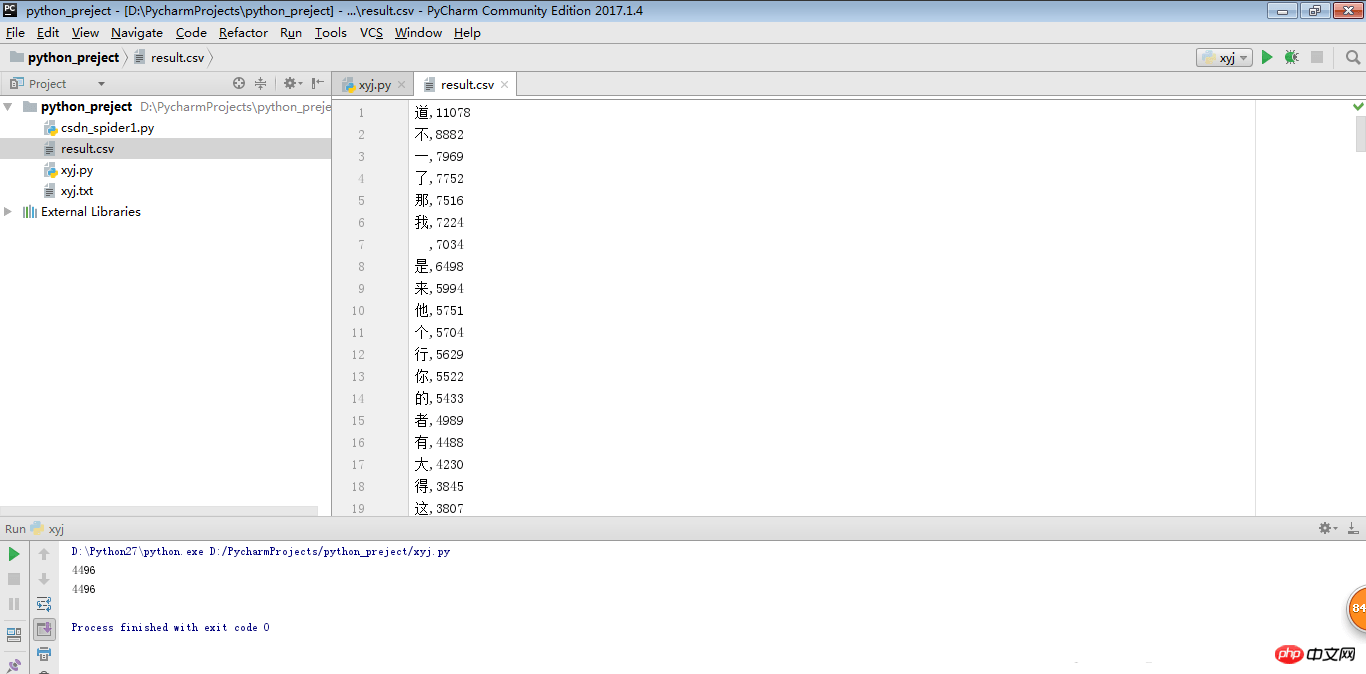
五、源代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
相关推荐:
Python文本特征抽取与向量化算法学习实例详解
Python文本相似性计算之编辑距离详解
以上就是Python文本统计功能之西游记用字统计操作的详细内容,更多文章请关注木庄网络博客!!
相关阅读 >>
Python通过公共键对字典列表排序(利用itemgetter函数)
解决Python requests库编码 socks5代理的问题
更多相关阅读请进入《Python》频道 >>

Python编程 从入门到实践 第2版
python入门书籍,非常畅销,超高好评,python官方公认好书。




