本文摘自php中文网,作者零到壹度,侵删。
在python写爬虫的时候,html.getcode()会遇到403禁止访问的问题,这是网站对自动化爬虫的禁止。这篇文章主要介绍了Angular2进阶之如何解决爬虫出现403问题的办法,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧要解决这个问题,需要用到python的模块urllib2模块
urllib2模块是属于一个进阶的爬虫抓取模块,有非常多的方法
比方说连接url=http://blog.csdn.net/qysh123
对于这个连接就有可能出现403禁止访问的问题
解决这个问题,需要以下几步骤:
1 2 3 4 5 |
|
其中User-Agent是浏览器特有的属性,通过浏览器查看源代码就可以查看到
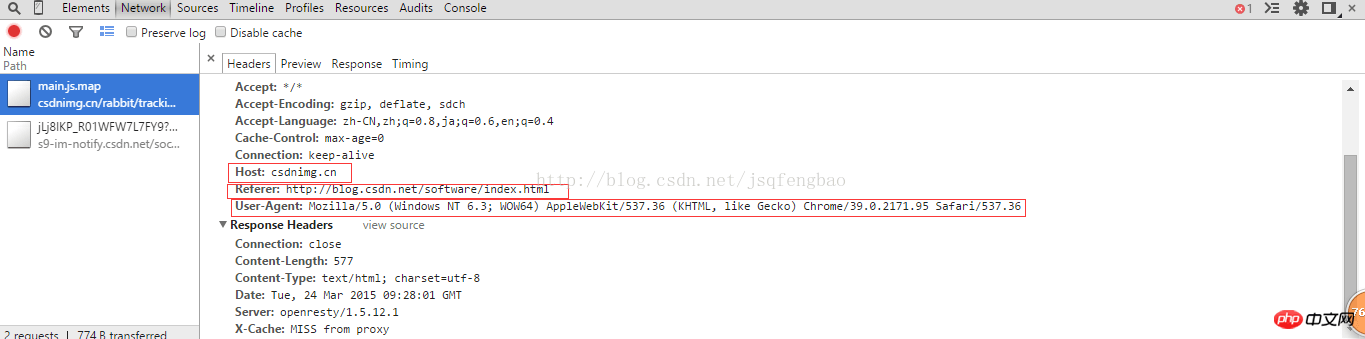
然后html=urllib2.urlopen(req)
print html.read()
就可以把网页代码全部下载下来,而没有了403禁止访问的问题。
对于以上问题,可以封装成函数,供以后调用方便使用,具体代码:
相关阅读 >>
更多相关阅读请进入《Python》频道 >>

Python编程 从入门到实践 第2版
python入门书籍,非常畅销,超高好评,python官方公认好书。




