感受下谷歌翻译实现重大突破!
对此,网友们都炸了,特别是学翻译的小伙伴们:
@猞猁与兔狲 作为一个翻译,看到这个新闻的此时此刻,我理解了18世纪纺织工人看到蒸汽机时的忧虑与恐惧……
@李某正在潜逃 换言之···做翻译的人现在开始要被第三次工业革命淘汰了?
@咖喱枝葉 外语系大学还没毕业的开始害怕
@帥_路 毕业论文英文版有救了!
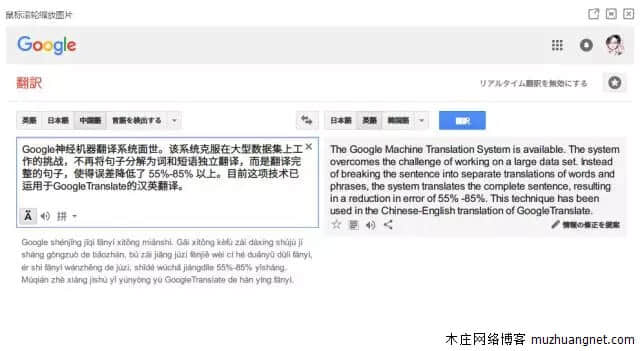
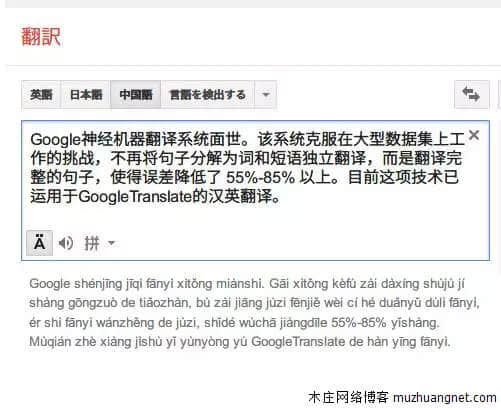
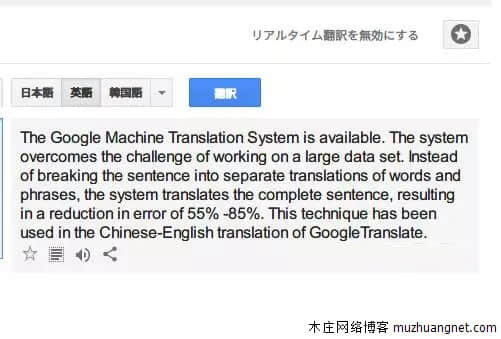
谷歌翻译的重大突破是什么?这一切是如何发生的?其实昨天谷歌就已经发表了相关论文,介绍了自己最新的神经机器翻译系统(GNMT),以及新系统的工作原理。 前天(9月27日),谷歌在 ArXiv.org 上发表论文《Google`s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》,介绍谷歌的神经机器翻译系统(GNMT)。
昨天(9月28日),谷歌 Research Blog 发布文章对该研究进行了介绍,还宣布将 GNMT 投入到了非常困难的汉语-英语语言的翻译生产中,引起了业内的极大的关注。
以下为谷歌发出的介绍文章 十年前,我们发布了 Google Translate(谷歌翻译),这项服务背后的核心算法是基于短语的机器翻译(PBMT:Phrase-Based Machine Translation)。
自那时起,机器智能的快速发展已经给我们的语音识别和图像识别能力带来了巨大的提升,但改进机器翻译仍然是一个高难度的目标。
今天,我们宣布发布谷歌神经机器翻译(GNMT:Google Neural Machine Translation)系统,该系统使用了当前最先进的训练技术,能够实现到目前为止机器翻译质量的最大提升。我们的全部研究结果详情请参阅我们的论文《Google`s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》。
几年前,我们开始使用循环神经网络(RNN:Recurrent Neural Networks)来直接学习一个输入序列(如一种语言的一个句子)到一个输出序列(另一种语言的同一个句子)的映射。其中基于短语的机器学习(PBMT)将输入句子分解成词和短语,然后在很大程度上对它们进行独立的翻译,而神经机器翻译(NMT)则将输入的整个句子视作翻译的基本单元。
这种方法的优点是:相比于之前的基于短语的翻译系统,这种方法所需的工程设计更少。当其首次被提出时,NMT 在中等规模的公共基准数据集上的准确度,就达到了可与基于短语的翻译系统媲美的程度。
自那以后,研究者已经提出了很多改进 NMT 的技术,其中包括模拟外部对准模型(external alignment model)来处理罕见词,使用注意(attention)来对准输入词和输出词 ,以及将词分解成更小的单元应对罕见词。
尽管有这些进步,但 NMT 的速度和准确度还没能达到成为 Google Translate 这样的生产系统的要求。
我们的新论文描述了怎样克服让 NMT 在非常大型的数据集上工作的许多挑战、如何打造一个在速度和准确度上都足够能为谷歌 用户和服务带来更好的翻译体验的系统。
相关阅读 >>
更多相关阅读请进入《谷歌翻译》频道 >>




