本文摘自雷锋网,原文链接:https://www.leiphone.com/category/academic/x8ZL9n4VadoDY7hD.html,侵删。

经济学家熊彼特认为,所谓创新就是要”建立一种新的生产函数”,即"生产要素的重新组合”, 就是要把一种从来没有的关于生产要素和生产条件的“新组合”引进生产体系中去,以实现对生产要素或生条件的“新组合”。目前,机器人就是新的生产要素,要妥帖地缝合在社会生活中。 后疫情时代的科学家与产业人士,已经找到机器人与人工智能发展的方向,我们将看到,他们会逐渐把重心放在技术发展的时速上,保证机器人在进击的道路上,适应这个时代的节奏。
今年的CoRL落下帷幕,这个专注于机器人领域的新秀,再一次将机器人前端研究推至大众面前。
今年的机器人研究有哪些看点?公开展示的11个机器人研究和最佳论文奖到底有何突破?与往年相比,今年的机器人研究有哪些不同?后续将会影响哪些产业?
带着这些问题,AI科技评论深剖了今年的CoRL会议,与大家共同探讨 「2021年最前沿的机器人研究」。
在公布今年最佳论文奖之前,CoRL展示了11个机器人项目,透露了本年度最受关注的机器人研究方向。

这11项中,其中四项为四足机器狗,即2,4,7,10,分别为瑞士ANYbotics的ANYmal 和杭州宇树科技A1。


在性能上,它们都利用了机载本体感受和外感受反馈,将感官信息和所需的速度命令映射到脚步计划中,实时、在线地适应未见过的地形环境,表现显著优于其他腿式机器人。除此之外,它们还能在一系列运动步态之间随意切换,以最小化其能量消耗。
而它们背后的无模型强化学习,也一举成为腿式机器人运动控制器开发中的最优方法。
具体来说,无模型强化学习指智能体与环境进行实时交互和探索,并直接对得到的经验数据进行学习,最终实现累积收益最大化或达到特定目标。它不需要拟合环境动态模型,只要与环境的实时交互,就可以保证智能体渐近收敛得到最优解。
拥有这种模型的四足机器狗,不仅能顺利走出实验室,还能在更复杂的场景中自我决策,成就名副其实的--“跟着感觉走”。
接着,在机器人感知领域,视觉领域的项目有两项,即1,3;触觉领域有三项,即6,8,9。
在CV领域,实时密集三维映射称为密集SLAM(Simultaneous localization and mapping,同步定位与建图),一直是机器人技术的主要挑战之一,问题包括估计传感器的自由度位姿和环境的三维重建。尽管目前存在RGB-D映射解决方案,但深度值不能简单地从传感器读取并融合,单目摄像机成为性价比最高的方案。


TANDEM框架的创新之处在于,它在摄像机跟踪方面优于其他基于学习的单目视觉里程计(VO)方法,并展现出实时三维重建的性能。
具体来说,它采用了一种新的跟踪前端,该前端使用由密集深度预测增量构建的全局模型渲染的深度图来执行密集直接图像对齐。其次,为了预测稠密的深度图,作者提出了级联视图聚合MVSNet (CVA-MVSNet),能够利用整个活动关键帧窗口,通过分层构造具有自适应视图聚合的3D成本量来平衡关键帧之间的不同立体基线。最后,将预测的深度图融合为一致的全局图,并以截断的带符号距离函数(TSDF)体素网格表示。
而iMAP模型,则是第一个使用神经隐式场景表示的 SLAM 系统,能够MLP 在没有先验数据的情况下在实时操作中进行训练,构建一个密集的、特定于场景的隐式 3D 占用和颜色模型。
除了视觉研究,机器人的触觉研究也在今年展现出不俗的研究势头。

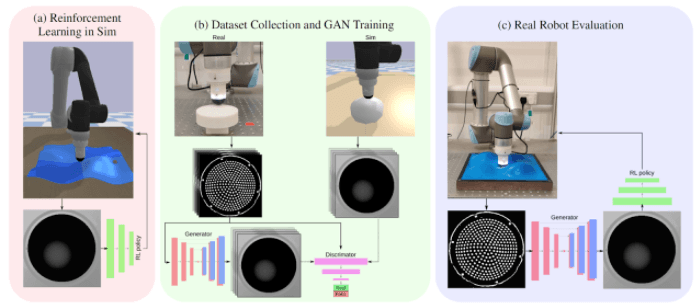

其中,ReSkin是一款利用机器学习和磁传感技术的触觉软传感器,能实现无源共形接触(conformal contact),又能根据传感器特性提供主动接触数据,可视化地表现其接触定位和力预测。
此外,为解决长期以来软传感器寿命短、退化快的问题,ReSkin在设计中将磁传感将电子电路从被动接口中分离出来,便于更换接口。
虽然目前的皮肤感知难以起步,但在现阶段,研究者不约而同将目光聚焦在“指尖感应”上,通过深度学习解读高分辨率的触觉数据,可实现对手持物体的精细控制和轻而稳的抓取。
最后,在机械臂运动规划的研究中,模仿学习成为今年热点。
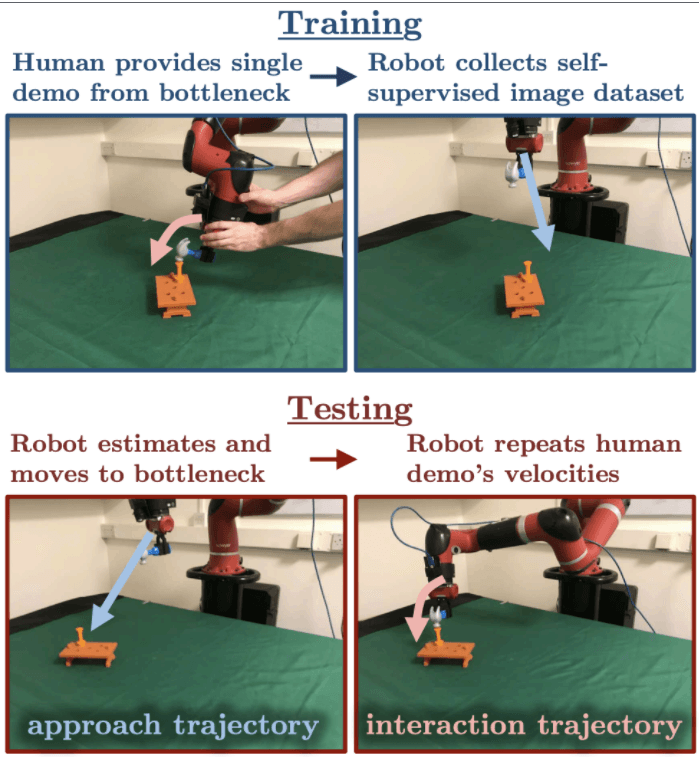

视觉模仿学习可以建模为一个状态估计问题,状态定义为对象交互开始时末端执行器的姿势。因此在学习中,无需使用大量演示或强化学习来明确学习策略,也无需储存对与之交互的对象的任何先验知识,而是训练一个自我监督的姿态估计器,可从单个人类演示中学习各种技能,同时还产生一个稳定且可解释的控制器。
而重头戏--最佳论文奖,则将研究聚焦在“灵巧手”上。
2 最佳论文奖:灵巧手
团队三人来自麻省理工学院计算机科学与人工智能实验室 (MIT CSAIL),分别为陈涛、徐捷,以及陈涛的博导Pulkit Agrawal。
巧的是,陈涛与徐捷同为2016年本科毕业,分别毕业于上海交通大学的机械工程及自动化专业与清华大学计算机科学与技术系。目前,两人同在MIT CSAIL实验室,各自师从于Improbable AI实验室的Pulkit Agrawal教授与计算设计和制造组(CDFG)的Wojciech Matusik教授。
在研究方向上,两人各有侧重,陈涛擅长机器人学习、操作和导航;徐捷擅长机器人仿真、设计协同优化与模拟现实,这为两人在灵巧手的合作上奠定了最基本的优势。

在CoRL会后,AI科技评论联系到陈涛,对项目的研究思路和三人的工作做了详细的了解。陈涛谈到,这个项目最大的贡献是为大家提供了一种研究思路:如何用强化学习和模仿学习训练灵巧手控制器,并且展示了机械手在最为极端的情况(手面朝下)下转动形状任意的物体。研究还发现,当灵巧手控制器足够鲁棒时,即使不知道物体形状信息,也可以以高成功率转动任意物体到指定朝向。
论文中表示,这个灵巧手有 24 个自由度,已通过无模型框架重新定位了超2000个形状各异的物体,具有非常高的通用性。

对于许多小的圆形物体,比如苹果、网球、弹珠,成功率接近 100%,对于更复杂的物体,如勺子、螺丝刀或剪刀,则接近 30%。研究发现,成功率因物体形状而异,接下来还要基于对象形状来训练模型来。
在性能上,这个灵巧手不仅能够借助桌子平台上向上和向下重定向物体,还能免除桌子支撑,在空中重定向,表现接近人手。

左边为物体应该定向的姿势,右边为定向演示。该图为借助桌子支撑的重定向展示

空中重定向,且手掌向下,需要考虑重力因素
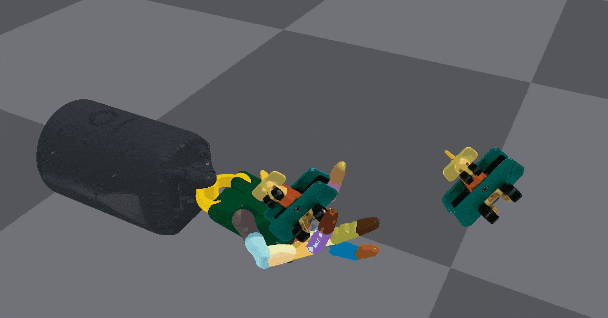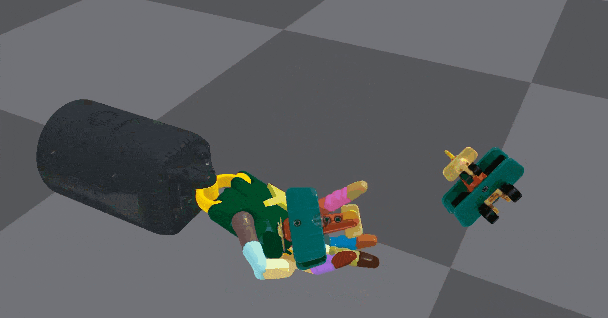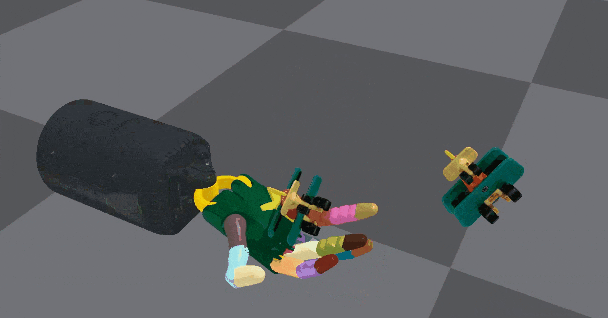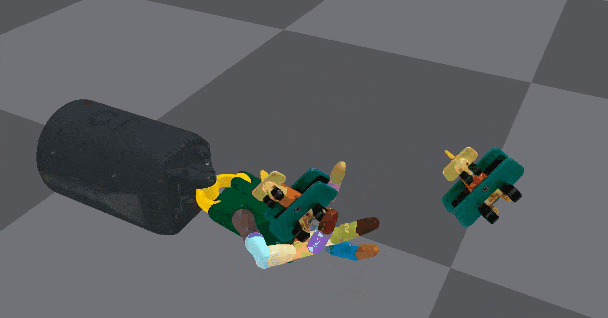
空中重新定向,且手掌向上,物体的形状复杂性加大。看这个灵活度,很适合盘核桃
在灵巧手研究领域,国内外都不乏研究者,但是目前使用最多的控制器,形式上无非是真空式吸盘或者平行夹爪。性能上,它们的优点在于抓取速度快且装载系统的成本低,但缺点在于自由度有限,灵活度不高。
陈涛举了一个例子:如果人手是钳子的形状,那么我们只能控制手部的打开和闭合,这种情况下,我们还能使用我们家里的很多工具吗,比如剪刀,螺丝刀等。而这,就是“灵巧手”研究所在。
“我们希望未来能进入人们日常生活的机器人,能够帮我们处理最基本的家务,比如说清理餐具,打扫厨房客厅, 收拾衣物等。那么我们现有的机器人具有这个能力吗?显然是还不具备的。这个涉及到很多原因,其中一个物理条件就是是缺少灵巧的机械手。”陈涛谈到。
那为什么要研究灵巧手重定向物体呢(转动物体到目标朝向)?其实这是一个很实用的技能:在我们生活中,拧螺丝,拧瓶盖等动作都可以描述为物体在手上发生位移,由一开始的水平朝向变为竖直朝向,如果用灵巧手来实现这一高频技能,机器人就会使用更多的工具,解决了大部分的场景应用问题。
从机器人面向复杂场景的应用到灵巧的末端控制器重定向研究,整个研究的转向是极其自然又合理的。陈涛谈到,灵巧手的研究源于自己和导师Pulkit Agrawal的一次饭后闲聊,随后快速推进,前后周期不过三、四个月。但因为期间还给导师新开的一门课程做助教花费了大量的时间,所以实际周期要更短。
在项目推进中,徐捷的加入则使得整个研究更加健备。囿于当时疫情情况,想要在真实机械手上模拟成为难题,于是研究物理仿真的徐捷辅助搭建环境,解决了灵巧手在仿真环境中的棘手问题。
涉及灵巧手的研究方法,陈涛谈到,灵巧手的自由度很高,如果用传统的控制理论以及建立动力学模型的方法,项目将很难推进。
灵巧手本身是一个高维度的控制系统,是否能跳过建立模型这一步,直接采用无模型的强化学习来训练灵巧手完成任务。
在一系列实验后,他们发现,如果只给控制器提供物体姿态,手指关节角,物体目标朝向的信息,那么控制器学习训练过程非常慢,而且最后训练完成后的成功率也不够高。所以他们又想到,如何能加快控制器的训练?
受2019年CoRL的一篇研究自动驾驶的论文的启发,他们想到,虽然最后测试过程中我们想要一个只依赖于物体姿态,手指关节角,物体目标朝向信息的控制器,但是训练过程中我们并不应该受限于只使用这些信息。也就是说,在训练过程中,我们可以使用更多的辅助信息来帮助加快控制器的训练。等到控制器学会这个技能后,再考虑去掉这些辅助信息。
陈涛又举了个例子,我们驾校学车的时候,科目二训练场地会有一些辅助线或者辅助杆帮助学员掌握侧方停车的技能。这些辅助线就是训练过程中的辅助信息,学员可以更快掌握侧方停车的方法,随后应用到现实世界中。
所以在陈涛他们的研究中也采用了相似的思路。
首先在训练过程中,给控制器提供了许多额外的状态信息,比如物体的速度信息。这些辅助信息的加入极大地加速控制器的训练。当训练好这样一个控制器后,就需要考虑怎么让控制器没有这些额外辅助信息也能工作。这时就用到了知识蒸馏(Knowledge Distillation) 或者说模仿学习(Imitation Learning)的技术。
他们把之前训练好的控制器作为“教师”,然后训练第二个控制器,即”学生”。“学生”控制器不需要使用额外的辅助信息作为输入,但通过模仿学习去模仿“教师”控制器的行为。最终,将获得一个聪明的“学生”控制器,也就是可以用来训练机械手转动大量形状不一的物体。在测试中,陈涛他们一共重定向了2000多个形状不同的物体。
解决了灵巧手学习框架的问题,接下来就是模拟现实应用。在真实场景中,手做任务时会有各种朝向,其中最极端的一种情况就是手掌朝下:不仅要操纵物体,还要避免重力因素导致物体脱落。
陈涛谈到,经过实验测试,我们发现现有的框架依然是够用的,只是需要在每次转物体开始前给物体姿态和手指关节角提供一个好的初始值,而非随机初始化。这里好的初始值是指能在初始时刻让手指触碰到物体,但是因为物体形状的复杂多样,灵巧手的高维状态空间,所以很难通过经典方法比如运动学逆解来获取这些好的初始值。
为了解决这一问题,他们首先训练了一个借助桌子而向下抓取物体的控制器。那么抓起之后,自然而然就获得了一个好的初始姿态设定。在此基础上,就可以用之前提到的框架去训练控制器。
通过这样的训练后,他们发现灵巧手朝下转动物体成功率仅有50%左右,实际上,即使与人相比,这个成功率已经很高了。陈涛说到,想象一下,你在闭眼时手掌朝下将一个任意形状的物体转到特定朝向,你的成功率有多高呢?
“但是我们依旧想进一步提高成功率,由此想到物体重力的影响。这就启发了我们下一个提高成功率的技巧:我们首先让机械手在真空(无重力)环境下训练,等到它学会怎么转东西了之后,我们逐渐增加重力加速度,并继续训练控制器直到它能在正常的重力环境下转动物体。我们称这个技巧为 「Gravity Curriculum」(重力课程)。”
最终,整个项目最出乎意料的发现是:无论是机械手朝上或朝下,都能成功训练一个控制器,使它在不知道物体形状的情况下还能够任意转动形状各异的物体。即论文中所说的“无感官预训练”。
最后,陈涛谈到:灵巧手是在机器人领域尚未被充分研究的的一项研究,希望我们的工作能让更多人关注到灵巧手操作这一领域,有更多人能进入这一领域共同促进灵巧手的发展。
但会议落幕,研究尚未结束。陈涛表示目前还会做一些拓展工作,比如将当前在仿真器里训练好的控制器迁移到真实的机械手上。“我们希望能在真实机械手上也能实现转动许多不同物体的目标。如果之后有其他人在这款灵巧手中加入视觉的信息或触觉的信息,使它的成功率更高,也要看在真实环境中的测试。”
未来,这款机械手可以转移到真实机器人系统,或应用到物流和制造业中,比如物体打包,插槽装配等;或应用于家庭场景中,处理杂物等。总之,它将使得机器人距离我们更近。
3 “无模型强化学习+模仿学习”组CP
总结来看,今年的CoRL中的研究有两种:一、基于无模型强化学习+模仿学习的机器人;二、基于视觉触觉等感知的机器学习系统。
为何“无模型强化学习+模仿学习”组了CP?
说到底,这是研究者们更加重视机器人在环境中的进化结果。
比如,和ANYmal机器狗在现实环境中在线进化不同,陈涛团队的灵巧手研究首先在仿真环境中训练,然后通过模仿学习一步一步提高泛化能力,并最终在真实的机械手上观测迁移性能。
同样,与陈涛团队的研究路径相比,ANYmal机器狗强调在现实环境中进化,从而获得更合适的反馈,比如得到更适合机器“狗”的反馈数据。
总之,无论是用有模型的训练框架,还是用无模型的训练框架;是在真实环境内中训练、在仿真环境中训练,各种方法并无优劣,而是是否适配特定的机器本体(仿人,仿狗等等)。
拿无模型强化学习来说,它成为今年的CoRL会议上频出的研究方法,其优势为何?
要解释何为无模型强化学习,首先要看向强化学习。
在定义中,强化学习作为机器学习领域中与监督学习、无监督学习并列的第三种学习范式,它是通过与环境进行交互来学习,最终将累积收益最大化。而强化学习算法分为模型化强化学习和无模型强化学习。
基于模型的强化学习算法是智能体通过与环境交互获得数据,根据数据学习和拟合模型,智能体根据模型利用强化学习算法优化自身的行为。
基于模型的强化学习算法的优点:由于智能体利用数据进行模型的拟合,因此智能体将数据进行了充分的利用,因为模型一旦拟合出来,那么智能体就可以根据模型来推断智能体从未访问过的区域。因为数据得到了最高的利用效率。智能体与环境之间的交互次数会急剧减少。用一个词来概括基于模型的强化学习算法就是Data efficiency。
从基于模型的强化学习算法的过程我们也可以很容易看到它的缺点:拟合的模型存在偏差,因此基于模型的强化学习算法一般不能保证最优解渐近收敛。
而在无模型强化学习中,智能体通过与环境进行实时交互学习收敛得到最优策略。由于没有拟合环境模型,所以智能体对环境的感知和认知只能通过与环境之间不断的交互。这个交互量多大呢?在陈涛的研究中使用了2000个形状各异的物体做仿真训练。如此多的交互次数使得无模型的强化学习算法效率很低,而且难以应用到实际物理世界中。
然而,跟基于模型的强化学习算法相比,无模型的强化学习算法有一个很好的性质,该性质是渐近收敛。也就是说,无模型的强化学习算法经过无数次与环境的交互可以保证智能体得到最优解。
然后从这点出发,再寻找提高训练速度的方法,比如添加更多的辅助信息,然后再通过知识蒸馏方法去掉辅助信息。先做加法、
随之而来的还有泛化问题,从仿真环境到现实环境,训练出在某个问题上泛化能力强的模型,才是机器学习最根本的目的。师生模仿学习成为这一阶段的利器。
此外,为何小数据模型受到追捧,或许还能从近年来的技术研究范式看出端倪:
相关阅读 >>
进博时刻|创新赋能健康未来!赛默飞携多款重磅首发新品亮相第四届进博会
更多相关阅读请进入《新闻资讯》频道 >>




