本文摘自雷锋网,原文链接:https://www.leiphone.com/category/academic/nSYY2nuroL7L7gdx.html,侵删。

今年 ACL 线下召开,谷歌研究员Sebastian Ruber也到现场参会了!
ACL 2022的举办地点是都柏林,Sebastian Ruber位于谷歌伦敦,过去不远。ACL之行结束后,他兴致冲冲地写下了他的参会感受,分享了他对几个学术动态的关注,包括:1)语言多样性和多模态;2)提示学习;3)AI 的下一个热点;4)他在大会中最喜欢的文章;5)语言和智能的黑物质;6)混合式个人体验。
以下AI科技评论对他的分享做了不改变原意的整理与编辑:

图注:ACL 2022 主题演讲小组讨论支持语言多样性的小组成员及其语言
ACL 2022 有一个主题为“语言多样性:从低资源到濒危语言”的主题赛道。除了赛道上的优秀论文,语言多样性也渗透到了会议的其他部分。史蒂文·伯德(Steven Bird)主持了一个关于语言多样性的小组讨论,其中研究人员会讲和研究代表性不足(under-represented)的语言。小组成员分享了他们的经验并讨论了语言之间权力动态等话题。他们还提出了切实可行的建议,以鼓励在此类语言上开展更多工作:创建数据资源;为资源匮乏和濒危语言的工作建立会议轨道;并鼓励研究人员将他们的系统应用于低资源语言数据。他们还提到了一个积极的进步,即研究人员越来越意识到高质量数据集的价值。总体而言,小组成员强调,使用此类语言需要尊重——对说话者、文化和语言本身。
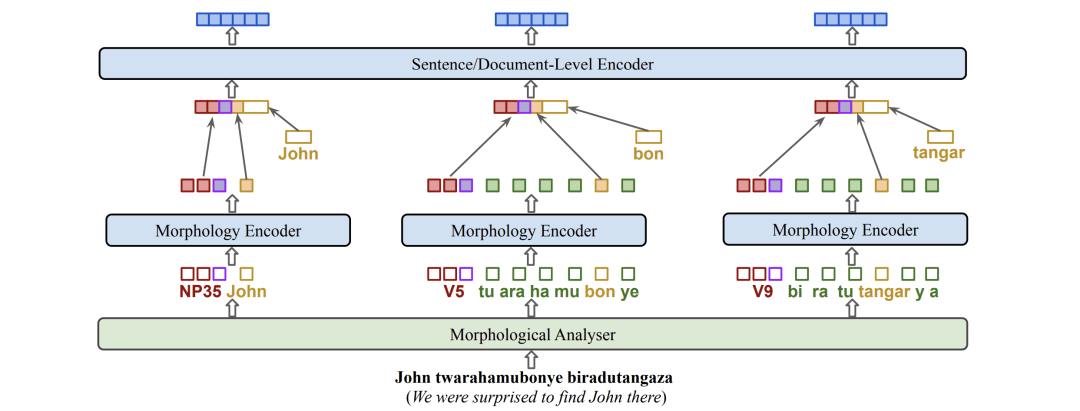
濒危语言也是 Compute-EL研讨会的重点。在颁奖典礼上,最佳语言洞察论文提出了KinyaBERT,这是一种利用形态分析器为基尼亚卢旺达语(Kinyarwanda)预训练的模型。而最佳主题论文为三种加拿大土著语言开发了语音合成模型。后者提供了一个多模态信息【译者注:此处的多模态是指语言的不同形态的信息,例如语音、文字、手语等等】如何有益于语言多样性的一个例子。


其他多模态论文利用电话表示来提高斯瓦希里语和基尼亚卢旺达语[1]中的实体识别任务的性能。对于低资源的文本到语音,也有工作[2]使用发音特征,例如位置(例如,舌头的正面)和类别(例如,浊音),这些特征可以更好地泛化到训练集中没有见到过的音素。一些工作还探索了新的多模态应用程序,例如检测美国手语中的手指拼写[3]或为声调语言翻译歌曲[4]。
多语言多模态研讨会在MaRVL数据集上主持了一项关于多语言视觉基础推理的共享任务。看到这种多语言多模态方法的出现特别令人鼓舞,因为它比前一年的 ACL 有所改进,其中多模态方法主要处理英语。
之后作者也受邀做了关于“将NLP系统拓展到下1000种语言”的口头汇报。

在受邀演讲中,作者除了介绍将NLP 系统扩展到下1000 种语言的三个其他挑战,即计算效率、真实语料上的评估以及语言变种(如方言)之外,他还强调了多模态的重要性。多模态也是由Mona Diab宣布的ACL 2022D&I特别倡议“60-60通过本地化实现全球化”的核心。该计划的重点是使计算语言学(CL)的研究能够同时被60 种语言应用,并且包括文本、语音、手语翻译、隐藏式字幕和配音在内的所有模态。该计划的另一个有用方面是整理最常见的CL术语并将其翻译成 60 种语言,而缺乏准确的科学术语表达对许多语言在CL的发展造成了障碍。
代表性不足的语言通常几乎没有可用的文本数据。两个教程侧重于将模型应用于此类低资源语言种。(1)使用有限文本数据进行学习的教程讨论了数据增强、半监督学习和多语言应用,而(2)使用预训练语言模型的零样本和少样本NLP教程涵盖了提示、上下文学习、基于梯度的LM任务迁移等。

教程(1):使用有限文本数据进行学习,一作为华人学者杨笛一
教程(2):零样本、少样本数据进行预训练
如何在不同语言中以最佳方式表示token是一个悬而未决的问题。一些工作采用了几种新方法来克服这一挑战。最佳语言洞察论文KinyaBERT利用了形态学分词方法。类似地,霍夫曼等人[5]提出了一种方法,旨在在标记化(tokenization)过程中保留单词的形态结构。该算法通过确定词汇表中最长的子字符串来标记一个单词,然后在剩余的字符串上递归。
Patil等人[6]并没有选择在多语言预训练数据中频繁出现的子词(这会使模型偏向于高资源语言),而是提出一种更偏向那些多种语言共享的子词的方法。CANINE[7]和 ByT5[8]都完全取消了标记化,直接对字节进行操作。
通常情况下,语言不仅在言语形式上有所不同,而且在文化上也有差异,其中包括说话者的共同知识、价值观和目标等。赫什科维奇等人[9]对——什么对于跨文化NLP的很重要——这一问题提供了一个很好的概述。举例来说,考察一种特定文化下和时间有关的语言表达,例如早晨,在不同语言中它可能指的是不同时间。
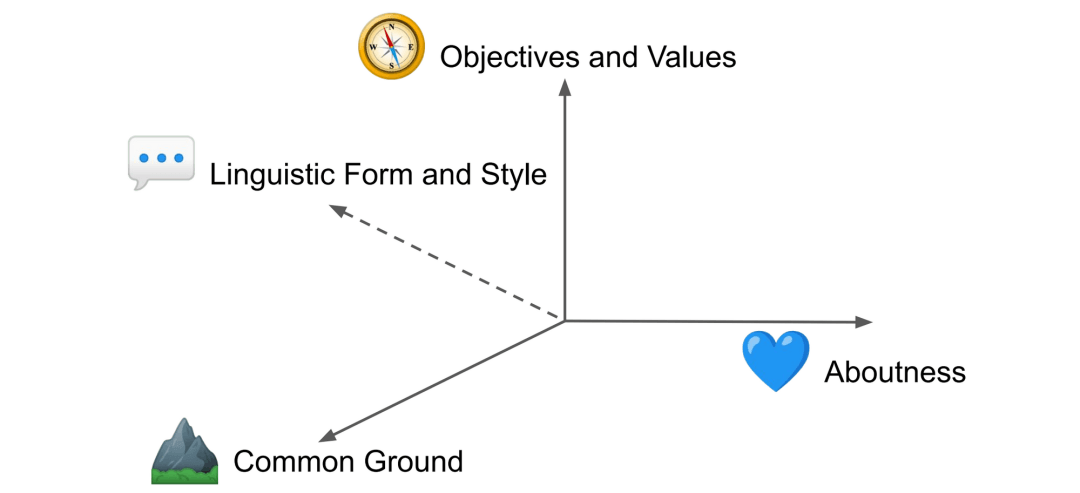
图注:不同文化语境下可能会变化的四个维度:言语形式、目标价值、共有知识和侧重传达的内容
除了上述提到的文章,作者还罗列了他自己比较喜欢的文章:
面向非洲语言的以非洲为中心的 NLP:我们在哪里以及我们可以去哪里。
文章讨论了NLP对非洲语言的挑战,并就如何应对这些挑战提出了切实可行的建议。它突出了语言现象(语调、元音和谐和连续动词构建)和非洲大陆的其他挑战(识字率低、正字法不标准化、官方语境中缺乏语言使用)。

质量概览:网络爬取的多语言数据集的审查。
这篇论文刚出版时,作者就写过它。文章对涵盖 70 种语言的大规模多语言数据集进行了仔细审核,并发现了许多以前未被注意到的数据质量问题。它强调了许多低资源语言数据集质量低下,一些数据集的标记甚至完全是错误的。

多语言模型零样本性能预测的多任务学习。
我们想知道模型的性能如何如果将它迁移到一种新语言,这可以有助于告知我们在新语言任务中需要多少训练数据。文章通过联合学习预测跨多个任务的性能,使性能预测更加稳健。这还可以分析在所有任务上,影响零样本迁移的特征。

而以下则是作者参与的和这个领域相关的论文:
一个国家,700多种语言:NLP对于印度尼西亚的代表性不足语言和方言的挑战。
文章提供了对于印度尼西亚中的700多种语言在NLP上的挑战的概览(印度尼西亚是全世界语言多样性方面第二多的国家)。这其中包含各种各样的方言、说话风格的差异、相互混合以及正字法的变化。作者们做出了实用性的建议,包括方言文本化,并将信息录入到数据库中。

通过词汇方面的适应手段,将预训练模型拓展到上千种更多的语言。
作者分析了不同的利用双语预料来为低资源语言训练合成数据的策略,并分析了如何把合成的数据和现有的数据结合(如果有的话)。文章结果发现,这要比直接翻译合成的数据效果要好(针对这些低资源语言的神经翻译模型也往往做的不好)。

NLP研究的单维偏差:朝向一个多维NLP研究的探索。
这是一篇综述反省性的文章,作者们定义一个称作“单一角落”(Square one)的NLP原型研究趋势,并通过检验461篇ACL‘21的做了口头汇报的论文,发现现在的NLP尽管已经超越了这一趋势,却还是存在研究维度单一的问题。他们发现几乎70%的文章仅仅使用英语进行评估,几乎40%的文章仅仅评估性能。仅仅6.3%的文章评估公正性、偏差等方向,以及仅6.1%的文章是“多维度”的,也就是他们在2个及以上的维度上都做了分析。
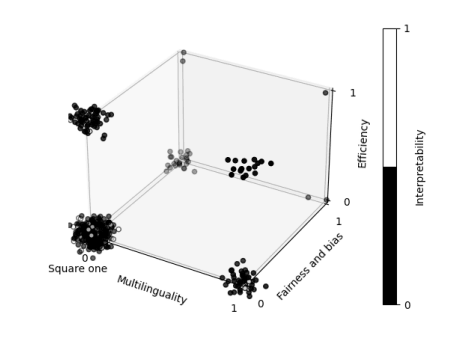
ACL’21文章研究内容的分类可视化,聚集现象表明研究的单一性
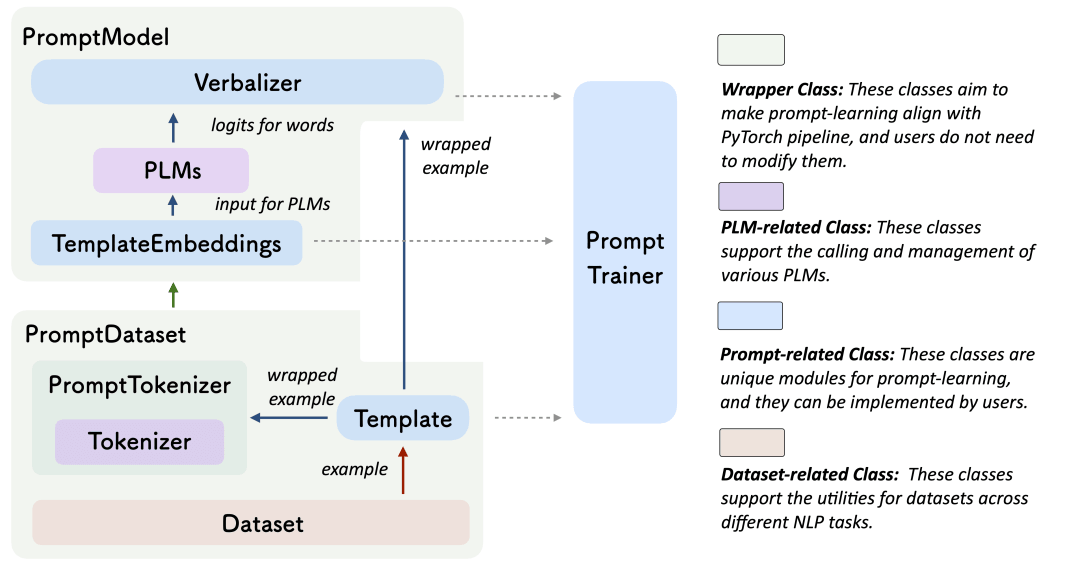
提示学习是另一个受到广泛关注的领域。最好的演示样例是由清华大学开发的OpenPrompt,这是一个用于提示学习的开源框架,可以轻松定义模板和语言器(verbalizer),并将它们与预训练好的模型相适配。
一个常见的研究思路是将外部知识纳入学习过程中。Shengding Hu[10]等人建议用知识库中的单词扩展语言器。Jiacheng Liu[11]等人先使用语言模型在少量样本的设置中生成相关的知识陈述,然后使用第二个语言模型来回答常识性问题。我们还可以通过修改训练数据来整合额外的知识,例如,通过在实体之后插入元数据字符(例如,实体类型和描述)[12]。
其他论文则提出了一些适合于特定应用的提示。Reif等人[13]提出一个可以处理带有不同风格例子的模型,用于风格迁移;而 Tabasi 等人[14]使用语义相似性任务的相似性函数得到特殊符号[MASK]标记的词嵌入。Narayan等人[15]则通过预测目标摘要之前的实体链来引导摘要模型(例如,“[ENTITYCHAIN] Frozen | Disney“),如下图所示。Schick等人[16]用包含某个属性的问题提示模型(例如,“上述文本是否包含威胁?”)以诊断模型生成的文本是否具有攻击性。Ben-David等人[17]生成域名和域相关特征作为域适配的提示。
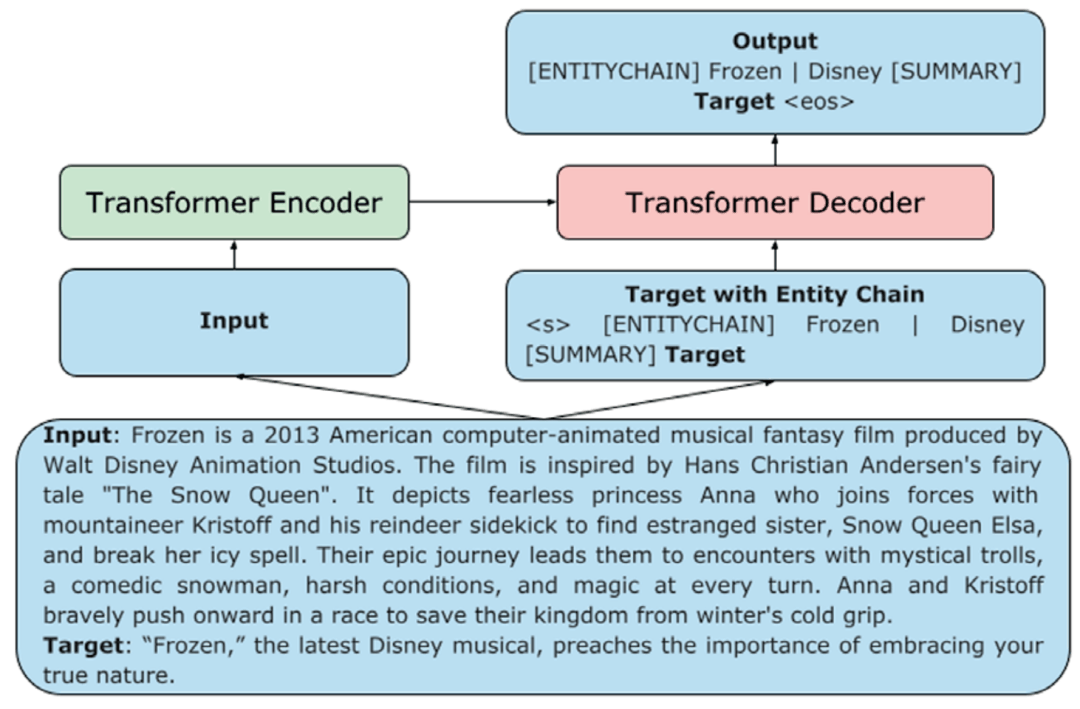
图注:Narayan等人[16]则通过预测目标摘要之前的实体链来引导摘要模型
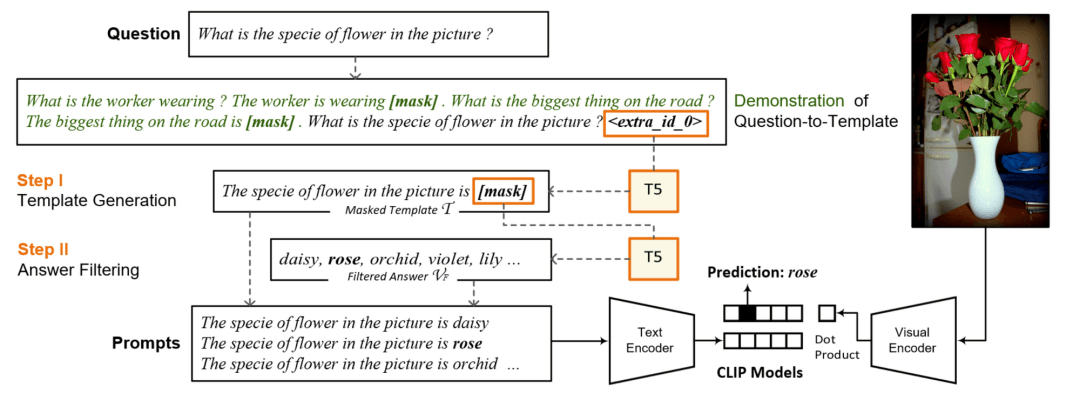
在和视觉相关的多模态设定中进行提示学习也受到了一些关注。Jin等人[18]分析了多样的提示在少样本学习设定中的影响。Haoyu Song等人[19]使用CLIP探讨了视觉-语言领域下的小样本学习。他们使用T5模型根据视觉问答的问题生成提示,并使用语言模型过滤掉不可能的答案。然后将提示与目标图像配对,并使用 CLIP计算图像-文本对齐分数。如下图所示。
最后,有几篇论文试图更好地理解提示学习。Mishra等人[20]探索重新构建指令的不同方法,例如将复杂任务分解为几个更简单的任务或逐条列出指令。Lu等人[21]分析模型对少样本顺序的敏感性。由于没有额外的开发数据就无法确定最佳排列,因此他们使用语言模型本身生成合成开发集,并通过熵确定最佳示例顺序。
以下论文是与作者合作的与少样本学习有关的工作:
FewNLU:对少样本自然语言理解的SOTA方法进行基准测试。
文章引入了一个评估框架,使小样本评估更加可靠,包括新的数据拆分策略。我们在这个框架下重新评估了最先进的小样本学习方法。我们观察到某些方法的绝对和相对性能被高估了,并且某些方法的改进会随着更大的预训练模型而降低,等等。

预训练语言模型中的记忆与泛化。
我们研究最先进的预训练模型的记忆和泛化行为。我们观察到当前模型甚至可以抵抗高度的标签噪声,并且训练可以分为三个不同的阶段。我们还观察到,预训练模型的遗忘比非预训练模型要少得多。最后,我们提出了一个扩展,以使模型对低频模式更具鲁棒性。

相关阅读 >>
全球首款android 13手机来了!谷歌pixel 7入网
招商证券全国客服电话大全已更新2023(实时/更新中)谷歌向欧盟投诉微软:云业务存在反竞争行为
谷歌正式发布旗下首款 tws 降噪耳机 pixel buds pro
更多相关阅读请进入《谷歌》频道 >>




