本文摘自雷锋网,原文链接:https://www.leiphone.com/category/academic/0n9DEOwmNsMdhS4I.html,侵删。

现实应用中,数据易得,而有标签的数据少有。
一般而言,当监督学习任务面临标签数据不足问题时,可以考虑以下四种解决办法:
1.预训练+微调:首先在一个大规模无监督数据语料库上对一个强大的任务无关模型进行预训练(例如通过自监督学习在自由文本上对语言模型进行预训练,或者在无标签图像上对视觉模型进行预训练),之后再使用一小组标签样本在下游任务上对该模型进行微调。
2.半监督学习:同时从标签样本和无标签样本中学习,研究者使用该方法在视觉任务上进行了大量研究。
3.主动学习:标注成本高,即便成本预算有限,也希望尽可能收集更多的标签数据。主动学习学习选择最有价值的无标签样本,并在接下来的收集过程中收集此类数据,在预算有限的情况下,帮助模型尽可能达到预期效果。
4.预训练+数据集自动生成:给定一个功能强大的预训练模型,可以利用该模型来自动生成更多得多的标签样本。受小样本学习大获成功的驱动,该方法在语言领域的应用尤其普遍。
1 什么是半监督学习?
半监督学习同时使用标签数据和无标签数据来训练模型。
有趣的是,现有关于半监督学习的文献大多集中在视觉任务上。而预训练+微调方法才是语言任务中更常见的范式。
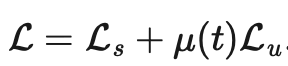
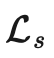
本文所提到的所有方法的损失,都由两部分构成:。其中监督损失
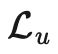
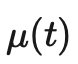
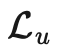
在样本全部为标签样本的情况下非常容易计算出来。我们需要重点关注如何设计无监督损失。加权项通常选择使用斜坡函数,其中t是训练步数,随着训练次数的增加,的占比提升。
声明:此文并不覆盖所有半监督方法,仅聚焦于模型架构调优方面的。关于在半监督学习中,如何使用生成模型和基于图的方法,可以参考《深度半监督学习全览》(An Overview of Deep Semi-Supervised Learning)这篇论文。

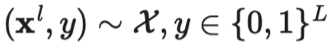


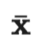
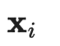
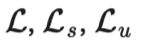
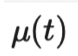
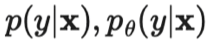
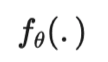
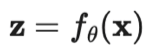
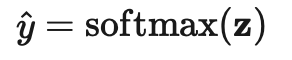
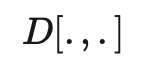
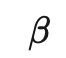
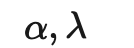

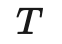
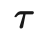
符号 含义 唯一标签的数量。 标签数据集,其中是真实标签的独热表示。 无标签数据集。 整个数据集,包括标签样本和无标签样本。 可以表示无标签样本, 也可以表示标签样本。 经过增强处理的无标签样本或标签样本。 第i个样本。 分别表示损失,监督损失,无监督损失 无监督损失权重,随着训练步数增加而增加。 给定输入情况下,标签数据集的条件概率。 使用加权θ生成的神经网络,即期望训练出的模型。 逻辑函数f的输出值的向量。 预测的标签分布。 两个分布间的距离函数,例如均方误差、交叉熵、KL散度等。 Teacher 模型权重的移动平均线加权超参数。 α为混合样本的系数 , 锐化预测分布的温度。 选择合格的预测结果的置信度阈值。
在已有研究文献中,讨论了以下几种假设来支撑对半监督学习方法中的某些设计进行决策。
如果两个数据样本在特征空间的高密度区域接近,它们的标签应该会相同或非常相似。
特征空间既有密集区域,也有稀疏区域。密集分组的数据点很自然地形成聚类。同一聚类中的样本应具有相同的标签。这是对假设1的一个小扩展。
类之间的决策边界往往位于稀疏的低密度区域,因为如果不这样的话,决策边界就会将高密度聚类分割为分别对应两个聚类的两个类,这就会导致假设1和假设2都失效。
高维数据往往位于低维流形上。尽管现实世界的数据可能是在非常高的维度上被观察到的(例如,真实世界的物体/场景的图像),但它们实际上可以被更低维的流形捕获,这种低维流形上会捕获数据的某些属性,并将一些相似的数据点进行紧密组合(例如真实世界的物体/场景的图像,并不是源自于所有像素组合的均匀分布)。这就使得模型能够学习一种更有效的表征方法去发现和评估无标签数据点之间的相似性。这也是表征学习的基础。关于此假设,更详细的阐述可参考《如何理解半监督学习中的流行假设》这篇文章。
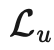
一致性正则化,也叫一致性训练,假设给定相同输入,神经网络中的随机性(例如使用 Dropout算法)或数据增强转换不会更改模型预测。本节中的每个方法都有一个一致性正则化损失:。
SimCLR、BYOL、SimCSE 等多个自监督学习方法都采用了这一思想。相同样本的不同增强版本,产生的表征都相同。语言建模中的交叉视图训练(Cross-view training )和自监督学习中的多视图学习(Multi-view learning)的研究动机相同。

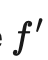
其中,指同一个神经网络应用不同的随机增强或dropout掩膜的取值。该损失使用整个数据集。
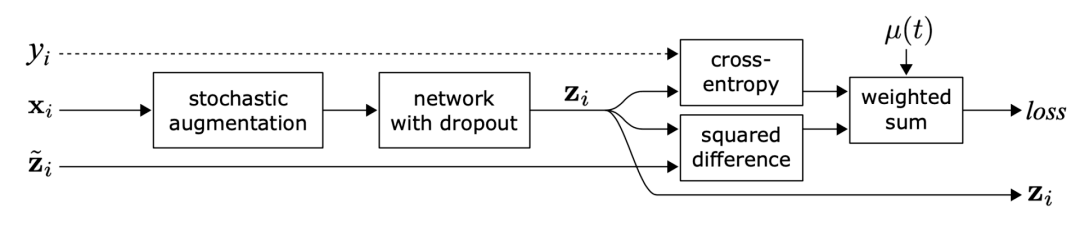
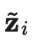
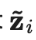
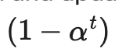
Π模型需要每个样本通过神经网络两次,这就使得计算成本增加一倍。为了减少成本,时序集成模型持续将每个训练样本的实时模型预测的指数移动平均值(EMA)作为学习目标,EMA 在每轮迭代中仅需计算和更新一次。由于时序集成模型的输出被初始化为0,因而除以进行归一化来纠正这一启动偏差。出于同一原因,Adam 优化器也有这样的偏差纠正项。
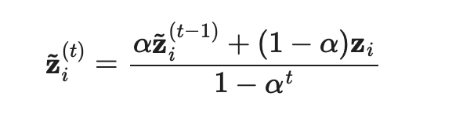

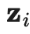
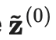
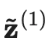
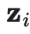
其中是在第t轮迭代中的集成预测,是在当前回合的模型预测。需要注意的是,由于=0,进行偏差纠正后,就完全等于在第1轮迭代中的模型预测值。
时序集成模型将追踪每一个训练样本的标签预测的指数移动平均值作为学习目标。然而,这种标签预测仅在每一次迭代中发生变化,当训练数据集很大时,这种方法就显得冗杂。
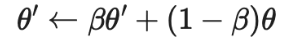
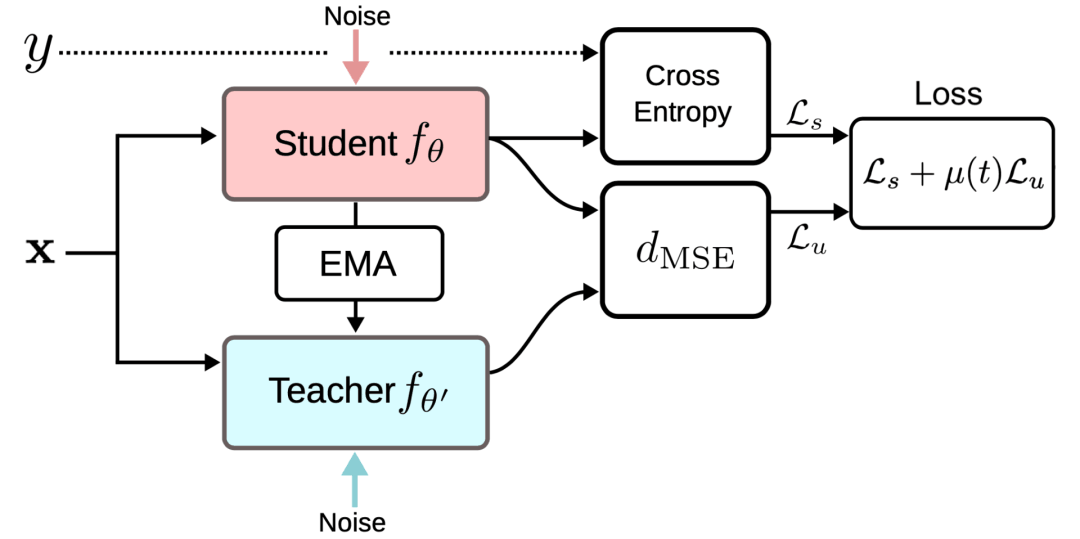
一致性正则化损失是Student模型和Teacher 模型的预测之间的距离,并且该差距应该最小化。Mean Teacher 模型能够提供比Student模型更准确的预测。该结论在实证实验中得到了证实,如图 4 所示。
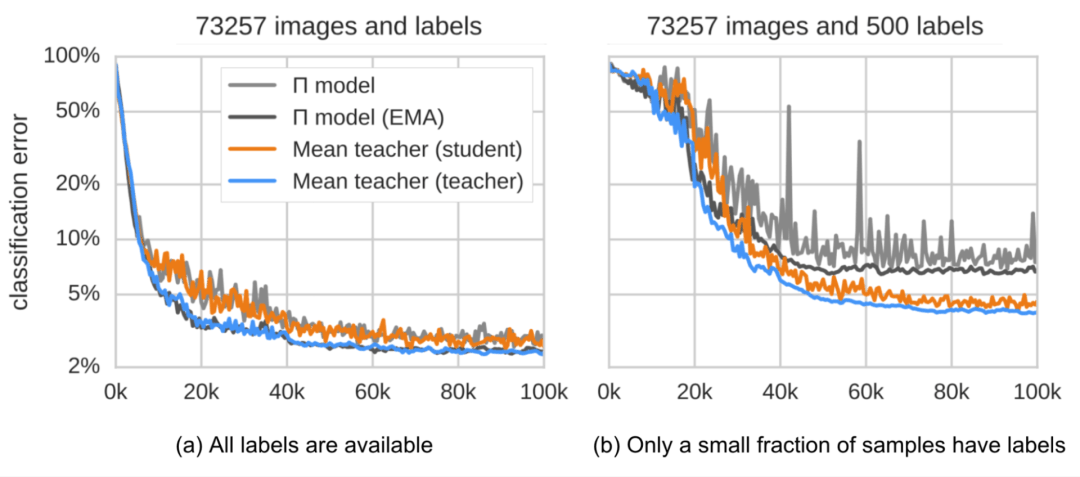
输入增强方法(例如,输入图像的随机翻转、高斯噪声)或对Student模型进行dropout处理对于模型实现良好的性能是必要的。Teacher模式不需要进行dropout处理。 性能对指数移动平均值的衰减超参数β敏感。一个比较好的策略是在增长阶段使用较小的β=0.99,在后期Student模型改进放缓时使用较大的β=0.999。 结果发现,一致性成本函数的均方误差(MSE)比KL发散等其他成本函数的表现更好。
4.将噪声样本作为学习目标
最近的几种一致性训练方法学习将原始的无标签样本与其相应的增强版本之间的预测差异最小化。这种思路与 Π 模型非常相似,但其一致性正则化损失仅适用于无标签数据。
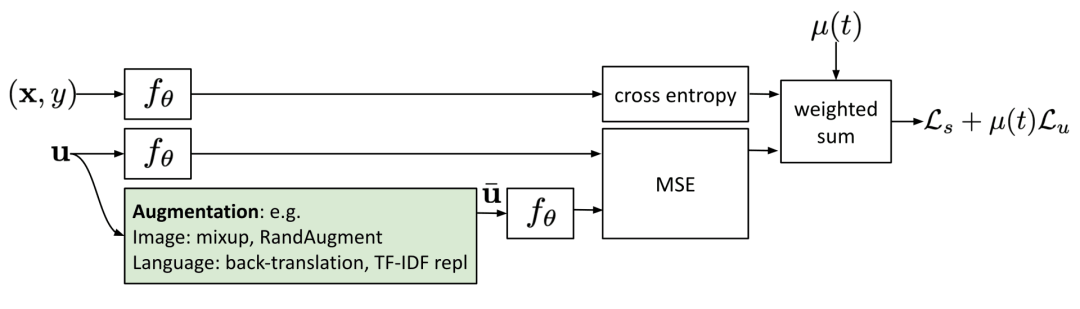
图5:使用噪声样本的一致性训练
在Goodfellow等人于2014年发表的论文《解释和利用对抗性样本》(Explaining and Harnessing Adversarial Examples)中,对抗性训练(Adversarial Training)将对抗性噪声应用到输入上,并训练模型使其对此类对抗性攻击具有鲁棒性。该方法在监督学习的应用公式如下:
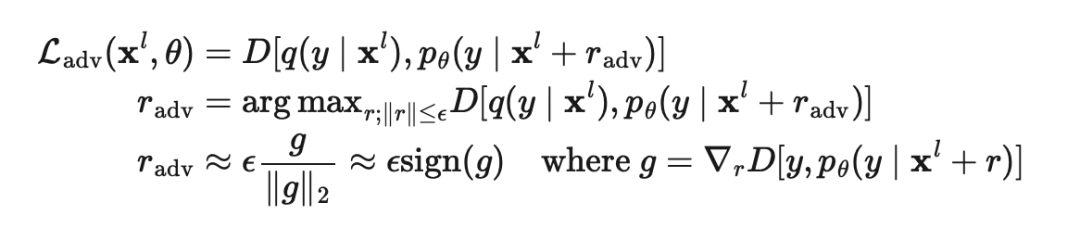
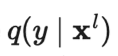
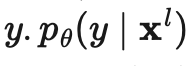
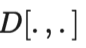
其中是真实分布,近似于真值标签的独热编码,是模型预测,是计算两个分布之间差异的距离函数。
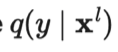


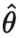
Miyato 等人在2018年发表的论文《虚拟对抗性训练:对监督和半监督方法都适用的正则化方法》(Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning)中提出虚拟对抗性训练(Virtual Adversarial Training,VAT),该方法是对抗性训练思想在半监督学习领域的一个延伸。由于是未知的,VAT 将该未知项替换为当前权重设定为时,当前模型对原始输入的预测。需要注意的是,是模型权重的的固定值,因而在上不会进行梯度更新。
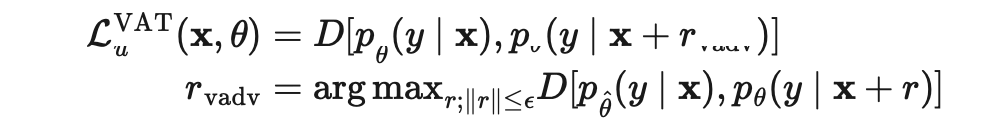
VAT 损失既适用于标签样本,也适用于无标签样本。它计算的是当前模型在每个数据点的预测流形的负平滑度。对这种损失进行优化能够让预测流形更加平滑。
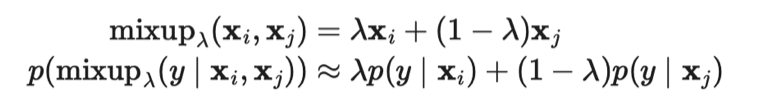
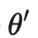
其中表示Mean Teacher 模型的θ的移动平均值。
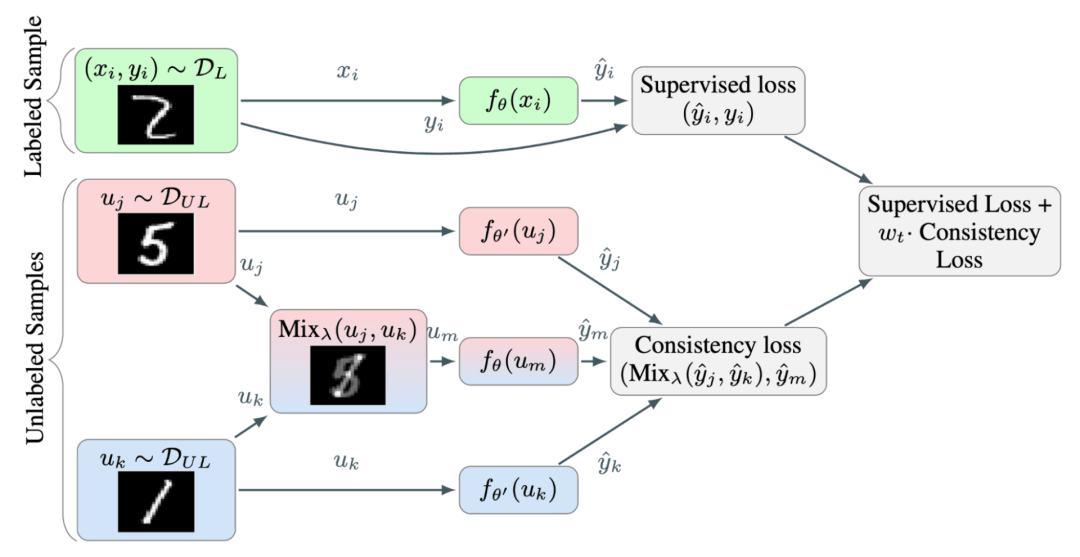
由于两个随机选择的无标签样本属于不同类别的概率很高(例如ImageNet中就有1000个目标类别),因此在两个随机无标签样本之间应用Mixup方法,就很可能生成在决策边界附近的插值。根据低密度分离(Low-density Separation)假设,决策边界往往位于低密度区域。
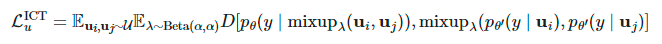
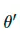
其中表示θ的移动平均值。
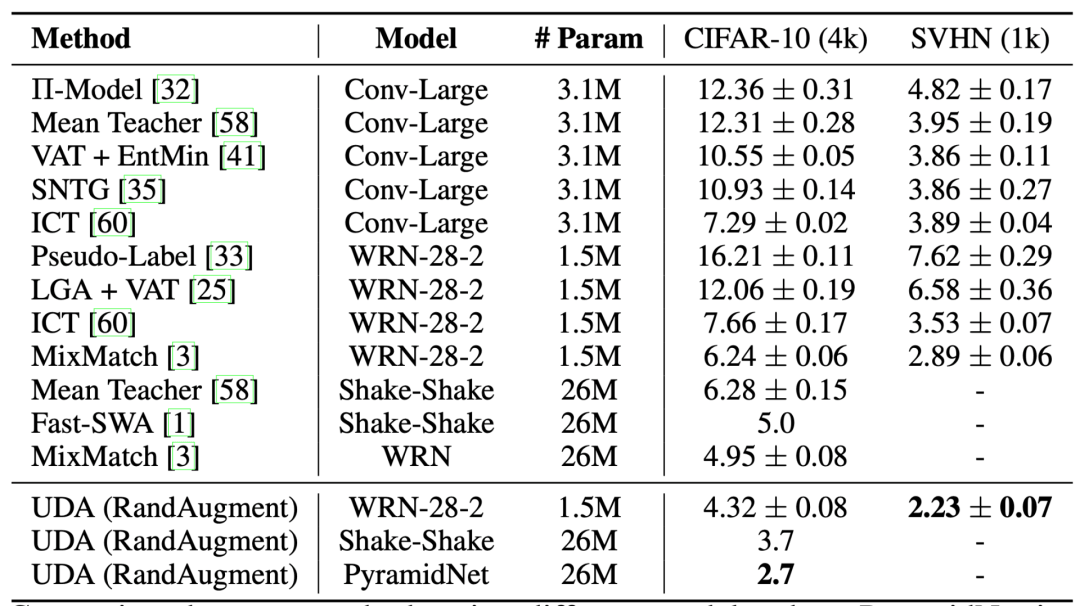
与VAT类似,Xie 等人在2020年的论文《一致性训练的无监督数据增强》(Unsupervised Data Augmentation for Consistency Training)中提出的无监督数据增强(Unsupervised Data Augmentation,UDA),学习给无标签样本和增强样本预测相同的输出。UDA特别聚焦于研究噪声的“质量”如何通过一致性训练来影响半监督学习的性能。要想生成有意义和有效的噪声样本,使用先进的数据增强方法至关重要。良好的数据增强方法应该能够产生有效的(即不改变标签)和多样的噪声,并带有有针对性的归纳偏置(Inductive Biases)。
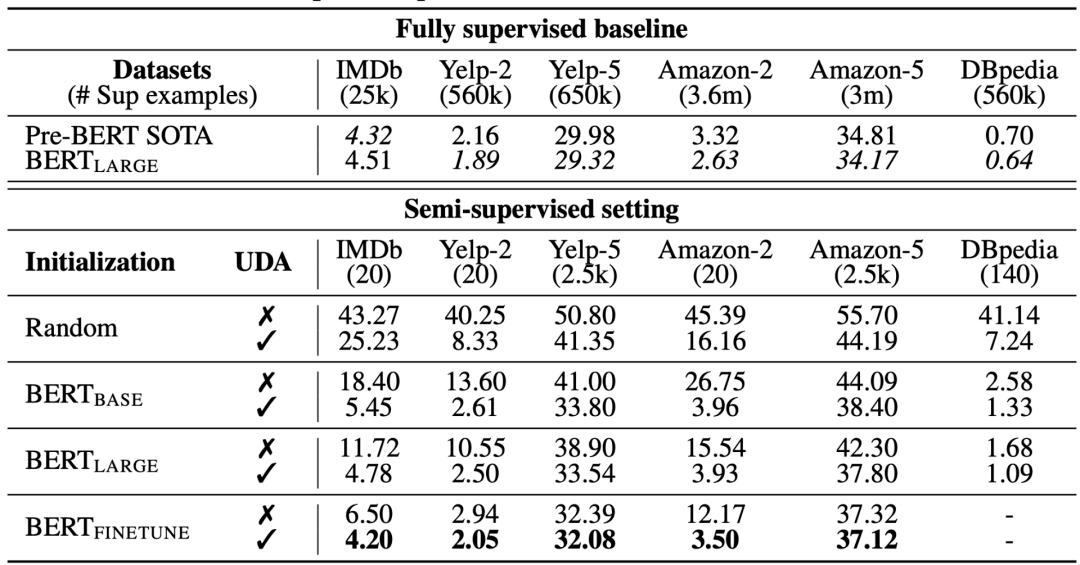
针对语言领域,UDA结合使用回译( back-translation)和基于TF-IDF的词替换(word replacement)两种方法。回译保留了高层次意义,但是不保留某些词本身,而基于TF-IDF的词替换则去掉TF-IDF分数较低的无信息性词。在语言任务的实验中,研究者发现发现UDA与迁移学习和表征学习是互补的;例如,在域内无标签数据上对BERT模型进行微调(即图8中的),能进一步提升性能。
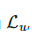
在计算 时,UDA可以通过使用以下三种训练技巧来优化结果:
低置信度掩膜(Low confidence masking):如果样本的预测置信度低于阈值,则对其进行掩膜处理。 锐化预测分布(Sharpening Prediction Distribution):在Softmax中使用低温来对预测概率分布进行锐化。 域内数据过滤(In-Domain Data Filtration):为了从大的域外数据集中提取更多的域内数据 ,研究人员训练一个分类器来预测域内标签,然后保留具有高置信度预测的样本作为域内候选样本。
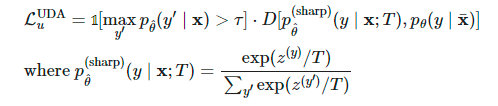
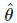
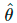
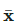
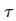
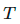
其中,是模型权重的固定值,与VAT中的一样,因而没有梯度更新,是经过增强的数据点,是预测置信度阈值,是分布锐化温度。
为什么伪标签能起作用?伪标签实际上相当于熵正则化,它将无标签数据的类概率的条件熵( conditional entropy )最小化,从而实现类之间的低密度分离。换句话说,预测的类概率实际上是计算类重叠,最小化熵相当于减少类重叠,从而降低密度分离。
相关阅读 >>
荣耀60系列正式发布:支持AI手势识别 vlog拍摄体验再升级
12/1传说对决 AIc-2021 one 对上 泰国dtn// 明天12/2的ag
蟑螂科技教育客服电话大全已更新2023(在实时/更新中)AI太强,人类危险?马斯克、图灵奖得主紧急呼吁暂停gpt-4模型后续研发
速览本周AI大事 | 阿里、商汤发布大模型,网信办“立规”生成式AI……
AI算力超越苹果a15!曝oppo自研6nm芯片马里亚纳x下放
更多相关阅读请进入《AI》频道 >>




