由于 LLM 本身性能有限,在反向验证过程中,单次解码会因随机性导致验证结果出现偏差,难以保证更准确的验证分数。为了解决这个问题,采样解码过程将重复 P 次,这样验证分数就可以更准确地反映模型对给定结论的置信度。
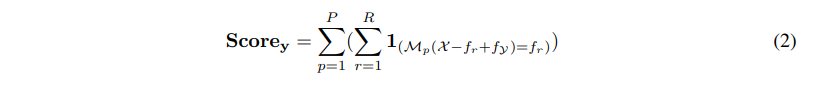
其中,1(.)为指示函数,从生成的 K 个候选答案中选择验证分数最高的一个作为结果,
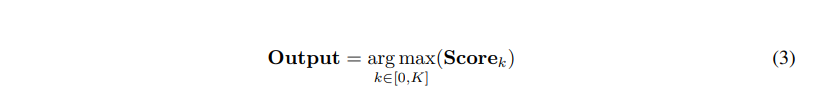
3 LLM 的自我验证能增强推理性能
此项研究评估了6个算术推理数据集,进一步证明了自我验证在常识推理和逻辑推理数据集上的有效性。这些数据集在输入格式方面高度异质:
算术,前两个是一步推理的数据集,后四个需要多步推理,解决起来比较有挑战性 常识,CommonsenseQA(CSQA)需要使用常识和关于世界的知识才能准确回答具有复杂含义的问题,其依赖于先验知识来提供准确的响应 逻辑,日期理解要求模型从一个上下文推断日期
研究人员在实验中测试来原始 CODEX 模型和 Instruct‑GPT 模型,此外还通过使用 GPT‑3 进行分析实验,研究了不同参数级别对可验证性的影响,LLM 的大小范围为 0.3B 到 175B 。这些实验使用了 OpenAI 的 API 来获得推理结果。
实验结果表明,使用了自我验证的两个模型在多个任务中实现了 SOTA 性能。

图 5:推理数据集上的问题解决率(%)
可以看到,自我验证在算术数据集上实现了1.67%/2.84%的平均改进,并为常识推理和逻辑推理任务带来了少量优化。此外,自我验证还直接导致高性能 Instruct‑GPT 模型结果平均增加2.33%,这表明,具有强大前向推理能力的模型也具有很高的自我验证能力。
研究人员进一步发现了以下几个关键结论。
可用条件越多,验证准确性越高
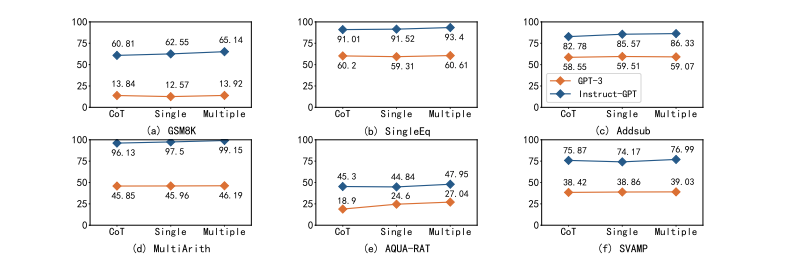
图 6:单条件验证与多条件验证的问题解决率(%)比较
图 6 中观察了对六个不同算术数据集使用单一条件掩码的效果:由于这些数据集输入中的每个数字都可以被视为一个条件,因此可以研究增加验证条件数量的影响。经大多数实验可发现,多条件掩码比单条件掩码表现更好,并且都比原始 CoT 表现更好。
模型越大,自我验证能力越强
图 7:不同尺寸模型的自我验证能力
图 7显示了参数从 0.4B 到 175B 的 GPT‑3 模型能力。实验结果表明,当参数较小时,模型的自验证能力较弱,甚至不如 CoT 的原始性能。这说明,模型的自我验证也是一种涌现能力,且往往出现在更大的模型中。
思维链提示很少并不影响自我验证能力
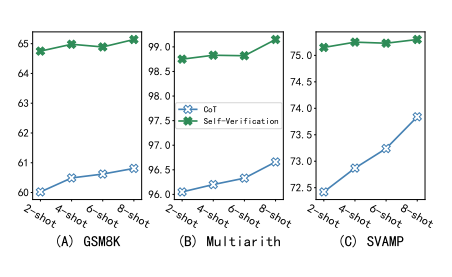
图 8:2 次提示和8 次提示的问题解决率(%)比较
图 8 所示的实验结果显示了不同的提示量对性能的影响。可以看到,自我验证在较小的样本中表现出更大的稳健性,甚至低至 2 次,这时候其 8 次提示的性能是 99.6%,而 CoT 只有 98.7%。不仅如此,即使只有 4 个提示(2 个 CoT 提示+ 2 个自我验证提示),自我验证也明显优于 CoT 8 次提示,突出了自我验证在数据有限情况下的重要性。

图 9:不同验证方式的提示对比
与其它方法相比,条件掩码的自我验证性能更优
有另一种方法可以验证模型答案的正确性:真-假项目验证,这以方法是模型对所有条件进行二分判断,如图 12 所示,不覆盖任何条件。此研究还提供了一个反向推理的例子,并尝试让模型自动从结论是否满足条件进行反向推理,但实验结果如图 10 所示,真-假项目验证的性能,要落后于条件掩码验证的性能。
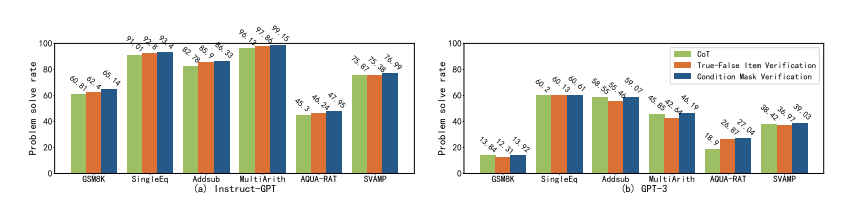
图 10:6 个算术数据集的问题解决率(%)条件掩码验证和真-假项目验证的比较
为了理解这种差距的原因,研究分析了具体案例,如图 11 所示,结果表明:(1)缺乏明确的反向推理目标导致模型再次从正向推理,该结果没有意义、并且不利用现有的结论;(2)真-假项目验证提供了所有的条件,但这些条件可能会误导模型的推理过程,使模型没有起点。因此,更有效的做法是使用条件掩码验证,从而更好地激发模型的自我验证能力。

图 11:一些实际生成案例进一步展示了不同验证方法的影响
LLM 的自我验证能纠错,但可也能「误伤」
图 12 展示了 LLM 使用自我验证来验证其自身结果的详细结果:
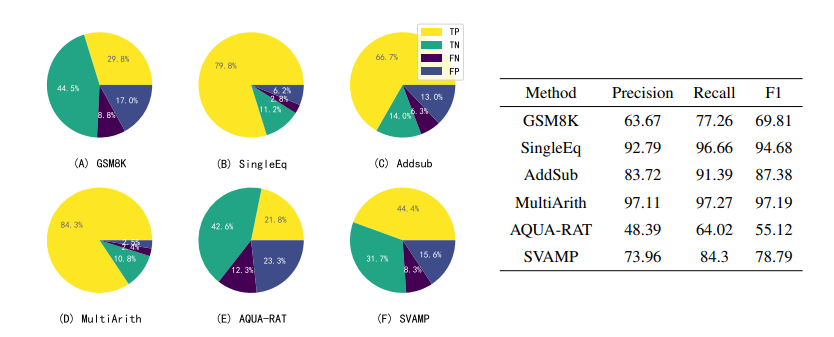
图 12:使用 Instruct‑GPT 为八个数据集中的每一个生成了五组候选答案,然后利用 Instruct‑GPT 的自我验证 能力,对它们进行一一判断和排序
左边的扇形图显示了自我验证产生的候选结论的预测结果。LLM 在每次提示中产生1-5个候选结论(由于 LLM 的自洽性,可能会产生相同的候选结论),这些结论可能是正确的,也可能是错误的,再通过 LLM 自我验证来检验这些结论,并将其类为真阳性(TP)、真阴性(TN)、假阴性(FN)或假阳性(FP)。可以发现,除了 TP 和 TN 之外,还有大量的 FN,但只有少量的 FP。
右边的表格显示了召回率明显高于准确率,由此可以说明,LLM 的自我验证可以准确剔除不正确的结论,但也可能将一个正确结论错误地认为是不正确的。这可能是由于反向验证时方程错误或计算错误造成的,这一问题将在未来解决。
最后总结一下,这项工作提出的自我验证方法能够让大型语言模型和提示来引导模型验证自己的结果,能提高 LLM 在推理任务中的准确性和可靠性。
但需要注意的是,这些提示是人为构造的,可能会引入偏差。所以方法的有效性会受到 LLM 产生的候选结论中正确答案的存在的限制,因此取决于模型正确前向推理的能力。
此外,该方法涉及生成多个候选 CoT 和结论,这对于 LLM 来说也存在计算资源的消耗。虽然它可以帮助 LLM 避免来自不正确的 CoT 干扰,但也可能无法完全消除推理过程中的错误。
更多内容,点击下方关注:
相关阅读 >>
蚂蚁财富理财客服电话大全已更新2023(在实时/更新中)微软专为网络安全专家推出AI聊天机器人
百度生成式AI产品文心一言邀请测试,五大场景、五大能力革新生产力工具
更多相关阅读请进入《AI》频道 >>




