本文摘自雷锋网,原文链接:https://www.leiphone.com/category/healthai/CIeOmsPoB1YlP0An.html,侵删。

近日,第六届全球人工智能与机器人大会(GAIR 2021)在深圳正式启幕,140余位产学领袖、30位Fellow聚首,从AI技术、产品、行业、人文、组织等维度切入,以理性分析与感性洞察为轴,共同攀登人工智能与数字化的浪潮之巅。
在医疗科技高峰论坛上,AIMBE Fellow、深圳理工大学计算机科学与控制工程院院长潘毅以《人工智能在生物医疗学工程中的应用》为题,分别讲述了医药研究中的数据特征、AI应用生物医学的研究案例,以及知识和数据对医疗AI的重要性。
今年2月,潘毅教授当选为美国医学与生物工程院院士。
他同时是英国皇家公共卫生学院院士、乌克兰国家工程院外籍院士、英国工程技术学会会士,在计算机和生物信息领域已发表250多篇SCI期刊论文,其中100多篇发表于顶尖期刊。
潘毅教授表示,当大家关注到事物之间的关系,用万物互联的思路解决问题,用AI探索万物互联,不仅能输出定量化病理诊断和疾病预后,还能推动病理研究向着更加自动化、更加精准的方向发展。
“今天很多的医药进步,已经不仅是通过临床实验做出来的,还是用数据分析出来的。人工智能的解释是逆向工程,这个工作非常复杂,但是非常值得研究。如果可以实现,那么,我们就可以找到压抑癌症、压抑肺病的某一个蛋白质,从而以靶标精准用药。”
以下为潘毅的现场演讲内容,雷峰网(公众号:雷峰网)&《医健AI掘金志》作了不改变原意的编辑及整理。
今天,我的演讲题目是《人工智能在生物医疗学工程中的应用》。人工智能是个大课题,生物医疗工程也很大。话题缩小一点,我们来谈谈AI制药。
01 生物医学研究已进入大数据时代
生物医学进入大数据时代,但是很多人处理数据的水平不高。原因在于计算机专家不懂生物,生物学家不懂编程,成果都不是很好。
对研究人员来说,常常面临工程上的“够用”和研究上的“低智”的矛盾。比如刚开始花了五百万提高到97%,如果还要再花五百万推进1%的进步,就会面临技术边际效应递减的问题。
很多人就放弃了,这是研究界很头痛的问题。
归根溯源,是什么在阻挠技术的进步?首先是数据。
计算机数据的结构巨大,我们耗用了大量的硬件和软件。大家熟知的超算中心、云计算平台、存储器,因为存储数量大、运算速度快、可以共享资源。
国家基因库里面放了很多基因数据,现在深圳理工大学也成为国家的生物中心之一(北上深各有一个)。

这个基因库不光是存储,还要提供很多工具和软件,即平台库,输入一个数据就出来结果,无需下载软件。
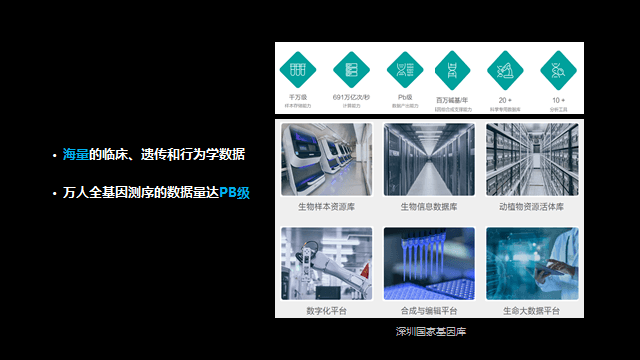
数据量大不是难题,难题是数据的异构性、多样性、增加速度快。
在医疗数据里,有影像数据、特征数据、医生诊断报告数据、病历数据,它们不仅是多模态数据,也是非结构化数据。

另外,医学数据还存在天然的不完整性、保密性、冗余性、时许性、多态性等特征。如何在浩瀚的数据原油里提炼转化,是非常重要的一点。

02 人工智能助力生物医学大数据研究
人工智能在大数据领域已经有很广泛的应用,比如用基因组学预测疾病,研究新冠病毒变异。
我的一位学生创立了一家公司,可以用一滴血或者唾液,预测人一辈子将会发生的疾病。
此外,在智能化时代,精准医药也变得十分重要,今天的主题是药,我着重讲一下AI在制药方面的应用,比如针对每个人的个体特征而控制药量。
回溯一下AI在医疗方面的应用。2017年,斯坦福大学教授做了一个研究,给皮肤照相来预测皮肤癌症,这也是今后我们要做疾病预测的一个方向。

2020年,哈佛大学成功用机器学习实现药物筛选,带动深圳几个药物筛选的AI公司发展起来。
我们的魏彦杰团队与药物所万晓春团队,与深圳市三院刘映霞团队合作,针对RdRp靶点,用人工智能技术筛选新冠病毒药物,发布了论文并应用到社区疫情预防中。


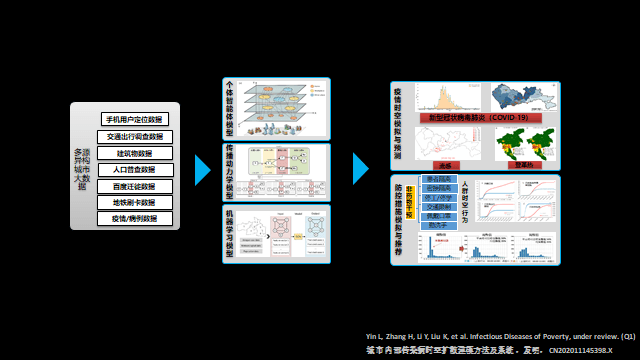
同样在疫情期间,尹凌研究员团队研发传染病时空预测与精准防控系统,基于大数据做疫情防控研究,形成了十余份内参文档和政策建议,为政府决策提供依据。
他们团队的方法是基于大规模手机信令数据、居民出行调查记录等多源时空大数据,对传染病时空传播过程进行城市级别的高分辨率模拟与预测,得出病毒的变种归规律、传播规律、感染规律等等。
• 新型冠状病毒2019-nCoV动物宿主朔源、及分子遗传变异规律研究
• 本地家庭、社区人群中传播效能、传播规律和驱动因素研究
• 人群大样本感染水平研究,确定病例隔离周期、评估隐性感染情况

所以,我们总是能够看到很多人工智能技术发挥医学价值的例子。但说到人工智能,Artificial intelligence,它到底是什么?
“假智能”?“伪智能”?还是“人造的智能”?
不管大家如何定义,我要说的一点是,我们不要神化AI。
第一代人工智能出现在三、四十年前。
在我求学时,我学习的“专家系统”是一个最典型的AI例子。它和中医诊断系统中的“因果说”很相似。比如说舌苔发黄,眼睛发红,很可能是得了感冒。专家系统也是一样的逻辑,就是用知识驱动知识。

那么,专家的知识从何而来?从老师那学,从书本上学,从经验里学。
那时候的AI技术为什么不成功?原因很简单,它只是一个很小的“玩具”。专家们只能搞点小玩意儿,发点小文章。在60年代到90年代,如果你说你是搞人工智能,是找不到的工作的。
那么,为什么现在的人工智能会被大家熟知?关键节点是出现了第二代AI系统。
如果说第一代AI系统是“照葫芦画瓢”,那么第二代AI系统是“无师自通”。

第二代系统由数据驱动,无需阐明数据之间的逻辑性,只需要放进大量的数据,利用深度学习就能找到数据背后的统计规律。
说得好听一点是深度学习,说得不好听就是算法,算法里面就是统计规律。
但是这时候的AI系统没有逻辑、也没有可解释性。
举个例子,AlphaGo第一次在围棋上打败人类,掀起了人工智能研究的热潮,但其实AlphaGo只是把五千年来所有的棋谱输入系统,然后在博弈的时候搜索最可能获胜的招数,以数据、算力和算法获胜。

当时我们也推出了一款新产品,命名为ShouZhuo,成功打败了AlphaGo,并尝试继续迭代算法,一举写出一篇好论文。不幸的是,两周以后Alpha Zero出来了。它不断跟自己对弈,不需要五千年的棋谱,练到最后棋法越来越好,把所有人类都打败了。
我们的想法是类似的,但是我们为什么不能成功呢?我们发觉,假如我们的算法也像Alpha Zero这样无休止对弈、训练,凭借我们实验室的硬件,大概要用1000多年的时间,1000多年之后这个算法肯定就没用了。
说到底,人工智能还不聪明,还是依靠“数据+硬件”驱动。在拼设备的年代,还能拼什么?
所以,这时出现了第三代AI系统。它将知识和数据结合起来,融汇了第一代AI系统和第二代AI系统。

举个例子,什么叫知识驱动?我女儿两岁的时候被蜜蜂蛰了一个大包,以后再见到蜜蜂就会跑开,这是数据驱动。什么是知识驱动呢?从小你家里人告诉你,猫不能碰、狗不能碰、蜜蜂不能碰、蛇不能碰,以后你见到这些东西就会远离。
但是知识驱动是有缺点的,因为图片是有限的,以后你遇到老虎、遇到大象还是会碰,因为没有先验知识。数据驱动也是有问题的,需要通过大量的数据完成“原始学习”,过程很慢。
如何将两种学习方式结合起来,将知识嵌入到机器脑中,这是第三代AI系统的问题。

举个例子,假如现在用100万张猫和狗图像训练好了一个神经网络,也就是设置好了参数,它会很轻松地分辨猫还是狗,但是准确性如何升高,如何再调整参数?

这时候就要用到梯度调节,这就是神经网络的概念。但是如何通过知识驱动,就是嵌入一个概念:比如我把“狗的耳朵比较大,猫的鼻子比较小”的概念放进去,这个算法就可以学得更好、更快。
所以,如何将知识图谱注入神经网络是很重要的课题。

举个例子,用神经网络抠出图片中的人。左边的图为无监督分隔,没有嵌入足够的知识图谱,所以分隔得十分粗糙。而右边的图为半监督分隔,事先学习了天是蓝的、云是白的、人脸是黄的,人的衣服是黑色的知识,图像识别的效果非常好。

同样的知识学习还体现在AI识别手写0—9这10个数字的实验中。
尽管每个人的笔迹都不同,写字风格千差万别,但假如我事先编写一组规则:有圆圈就是0、6、8、9,有一竖的就是1、4、7等等,这样AI的识别结果会好很多。

另一个方法是融合多模态数据,是把所有数据融合起来决策。
要预测什么菜好吃,我们说闻起来很香,炒起来看着很好吃,味道很甜美,口感很滑,颜色很漂亮,这就是好菜。
但是我要给你一个融合的算法,告诉你这个菜是臭的(臭豆腐),吃起来是很香的,颜色也是很糟糕的,你说是好还是不好?这个决策就很难了。
所以,这里面的融合,要决定哪个因素有多少的比例,大家投票说臭豆腐好不好,来训练这个神经网络。
比如应用在自闭症预测时,多模态融合的分析方法诊断率极高。
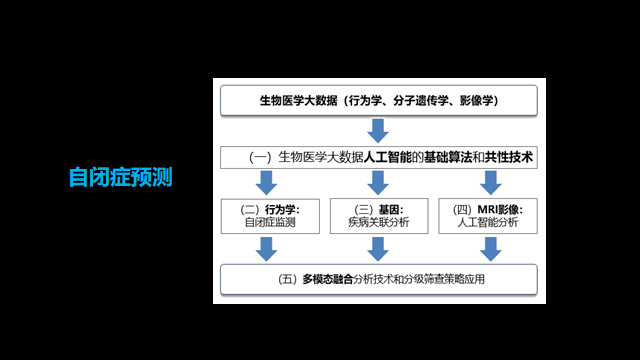
具体来说是三管齐下:
第一管,行为学分析;
第二管,基因分析,抽点血找到生物标记;
第三管,建立MRI影像,找到病灶。
相关阅读 >>
openAI推出新版图像生成器dall-e 3,10月份开发
openAI ceo:chatgpt周活用户数达到1亿、囊括92
ieee fellow杨铮:打破「视觉」垄断,无线信号为 AI 开启「新感官」
科亚医疗李育威:从临床需求出发,探索AI产品的商业化之路 | gAIr 2021
2022 剑桥 AI 全景报告出炉:扩散模型是风口,中国论文数量为美国的 4.5 倍
更多相关阅读请进入《AI》频道 >>




