本文摘自雷锋网,原文链接:https://www.leiphone.com/category/academic/iU3XTPqwV5hARizD.html,侵删。

知识是内涵,算力设施和训练框架是根基。
或许很难想象,从晶体管的每个具有确定性的0和1之间的变换,到最后也能变成一场科学实验般的探索。自人们用计算机证明四色猜想以来,这个硅质人造物就充满了无限的不确定性。
如今,深度学习再次向人类表明:计算机不是单纯地复刻人类的思维逻辑并加速的机器,它也可以产生新的思维方式。
如果说图像识别、机器翻译、语音生成等等应用都还是小试牛刀,其表现都还在人类预料之中,那么百亿甚至千亿参数规模的预训练模型展现的多任务能力,便是人类不断地体会惊讶的开始,也是接近理解自身的开始。
难以想象,当初仅仅作为NLP子领域之一的自监督学习语言模型,却在扩大了参数规模、采用了Transformer架构之后,在2018年横扫11项NLP任务,成为AI社区人尽皆知、3年时间引用量接近3万的BERT。
自那以后,基于预训练构造大型语言模型便成为一种基本操作,这是大模型时代开始的标志。
到如今,作为AI的底座能力,大规模预训练模型已成为全球AI领域的技术新高地。
12月8日,鹏城实验室与百度联合召开发布会,正式发布双方共同研发的全球首个知识增强千亿大模型——鹏城-百度·文心(模型版本号:ERNIE 3.0 Titan),该模型参数规模达到2600亿,是目前全球最大中文单体模型,在60多项任务中取得最好效果。
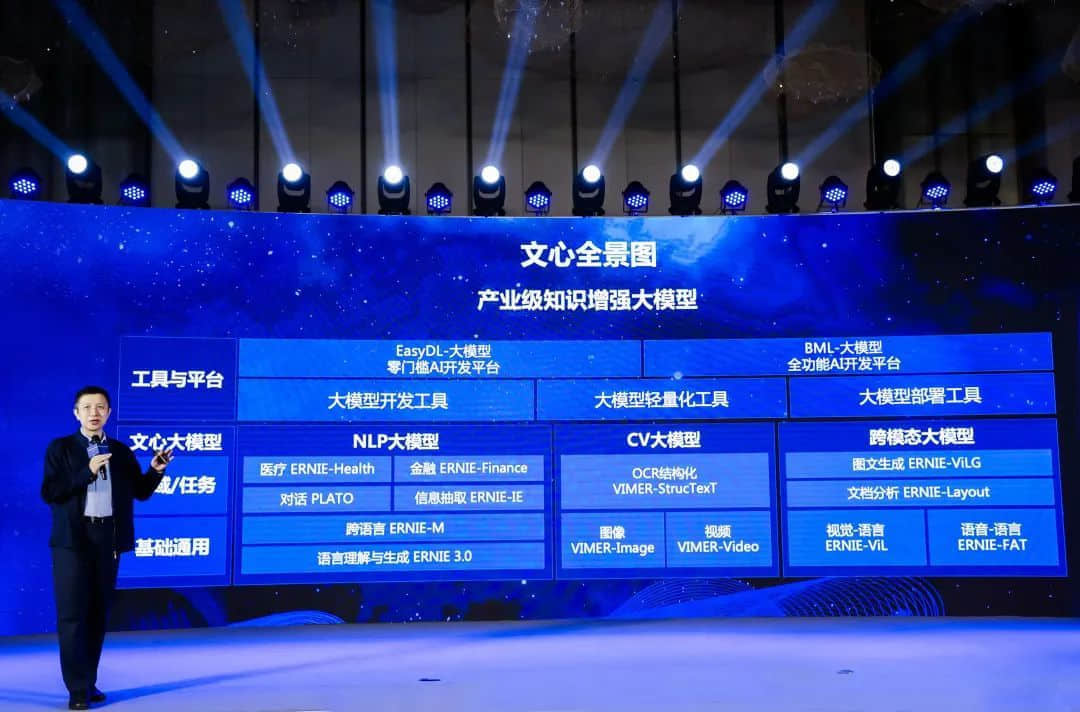
同时,百度产业级知识增强大模型“文心”全景图首次亮相。

中国工程院院士、鹏城实验室主任高文,百度首席技术官王海峰联合发布鹏城-百度·文心
目前,鹏城-百度·文心已在机器阅读理解、文本分类、语义相似度计算等60多项任务中取得最好效果,并在30余项小样本和零样本任务上刷新基准。
在鹏城-百度·文心背后,得益于鹏城实验室的算力系统 “鹏城云脑Ⅱ”和百度自研的深度学习平台“飞桨”强强联手,解决了超大模型训练的多个公认技术难题,使鹏城-百度·文心训练速度大幅提升,模型效果更优。
为解决大模型应用落地难题,百度团队首创大模型在线蒸馏技术,模型参数压缩率可达99.98%。
鹏城-百度·文心是百度文心“知识增强大模型”系列中十分重要的基础通用大模型。
为推动技术创新和落地应用,百度文心既包含基础通用的大模型,也包含了面向重点领域和重点任务的大模型,还提供丰富的工具与平台,支撑企业与开发者进行高效便捷的应用开发。
此次发布的鹏城-百度·文心在ERNIE 3.0基础上全新升级,后者此前曾在国际权威的复杂语言理解任务评测SuperGLUE上超越谷歌的T5、OpenAI的GPT-3等大模型,以超越人类水平0.8个百分点的成绩登顶全球榜首。
百度是业界少有的专注攻关知识增强型预训练大模型的企业,有知识加持的文本数据自然让模型更有内涵。此次升级的意义,不仅仅是简单地放大参数量,在这背后支撑的是坚如磐石的根基——也就是基础设施能力:鹏城实验室的E级超算,以及飞桨的超大模型训练与推理框架。
大规模预训练语言模型的基本训练方法是自监督学习,自监督学习语言模型的一般过程,是基于前文或上下文,来预测被掩盖的单词或短语,通俗来说就是做填空题。
为什么这样的学习范式有效?用反事实学习的原理简单理解就是,只要多试试一个单词出现与否对另一个单词出现与否的影响,就可以总结出两者的关联程度。
如果是在涉及现实知识的句子中训练,语言模型也可以学到这些知识。社区中也出现了从预训练语言模型中提取和构建知识图谱的研究。但问题在于,从这些模型中提取出来的知识可靠度有限。
人们发现,预训练语言模型倾向于依赖表面信号或统计线索来挖掘知识,并且可以很轻易地被愚弄,比如“鸟可以__”和“鸟不可以__”,模型都会输出“飞”。这些模型学习到的,似乎更多是语法规则,而不是现实知识,比如给定一组概念 {狗, 飞盘, 抓住, 扔},GPT2 会生成"狗将飞盘扔向足球运动员",T5 生成“狗抓住了飞盘,并扔向足球运动员”,这两者都不符合人类的常识。
这就向我们提出了这些问题:我们需要让大模型做这种事吗?现实知识的学习需要依靠大模型以外的手段吗?大模型学不到现实知识吗?
百度的回答是:需要;不需要;可以。
在医疗、法律等领域,AI的应用落地也在如火如荼地展开,而它们对结果的准确性要求严格。人们已经开始将大模型部署到这些领域中,在这些场景中涉及的现实知识非常专业和密集,自然不可能让只学会语法的算法来冒充专家。
引入现实知识,一个比较基本的方法是在模型本身引入归纳偏置,比如引入了空间平移对称性归纳偏置的多层感知机,就是卷积神经网络。但这种操作过于基本,也就是在先验地获取现实知识的同时,会过早限制模型的通用性,同时在理论探索上也非常困难。
另一个比较直接的方法是,保留模型本身的通用性,在数据和任务上入手。我们之前提到,预训练语言模型的一个缺点是,过分关注语法关联,因为语法关联在句子中出现最多,而对现实知识关联关注过少。
这其实也是因为,人类很少在日常交互中,强调和重复已知的知识,我们对于“鸟拍打着翅膀在天空飞翔”中隐藏的知识“鸟会飞翔是因为有翅膀”不会太在意,也不会刻意去表达,因为太过习以为常,这也就使得这些知识很少出现在模型接触的数据中。归根结底,人类和语言模型接触的并不是相同的数据源。
这种区别,就好像一个英语母语者可以轻易理解别人说的英语,而刚学习英语的中文母语者就需要字典的支持,字典凝结了大量的人类知识。
那么,为了学习现实知识,大模型需要什么样的“字典”?
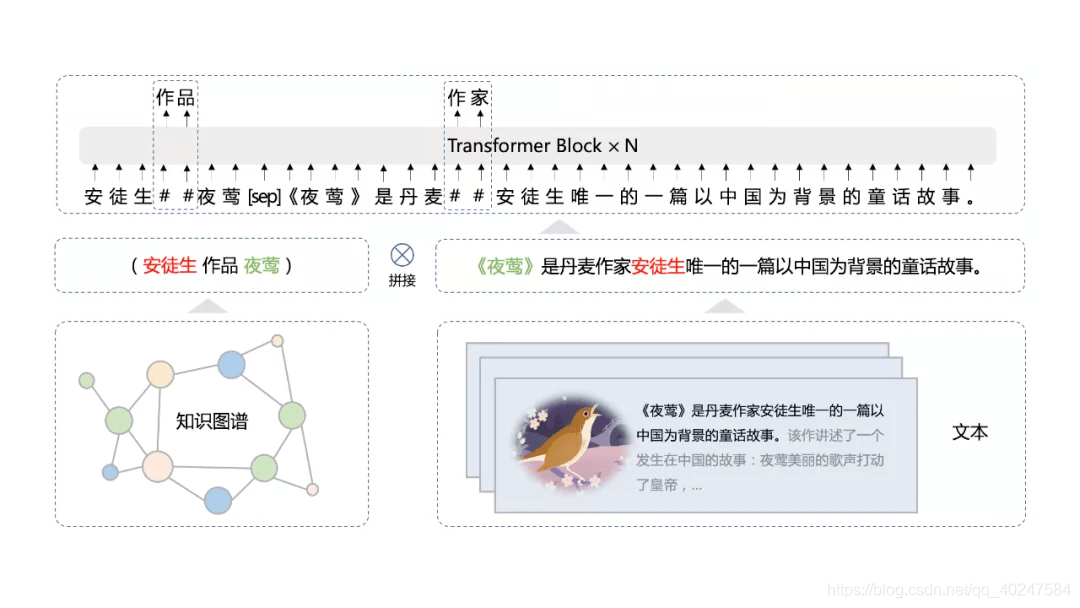
正如上图所示,对于“《夜莺》是丹麦作家安徒生唯一的以中国为背景的童话故事。”这句话,如果我们在输入中加入“安徒生 作品 夜莺”这样的实体关系,就可以让模型更多关注“作品”这样的关系,而不局限于关注“是”、“唯一的”等等常见的关系类词汇,从而对现实知识有更多的积累。
百度早就开始挖掘知识增强型预训练模型的潜力,2019年3月,百度就已经发布了第一代知识增强的预训练模型 ERNIE1.0。到今年7月,百度还训练出了百亿参数规模的知识增强型预训练模型——ERNIE 3.0。这是当时业界首次在百亿级预训练模型中引入大规模知识图谱。
这种方法被称为平行预训练方法(Universal Knowledge-Text Prediction),也就是将大规模知识图谱的实体关系与大规模文本数据同时输入到预训练模型中进行联合掩码训练。
这种做法可以促进结构化知识和无结构文本之间的信息共享,从而大幅提升模型对于知识的记忆和推理能力。
ERNIE 3.0在中文和英文数据集上均表现优越,其中在中文方面,ERNIE 3.0在54个数据集上均取得SOTA,同时零样本能力表现优越,另外在英文方面,ERNIE 3.0在国际权威的复杂语言理解任务评测SuperGLUE上超越谷歌的T5、OpenAI的GPT-3等大模型,以超越人类水平0.8个百分点的成绩登顶全球榜首。
通过知识图谱的加持,ERNIE 3.0已经学富五车,但它的能力展现需要稍加克制,否则便显得才华横溢而又语无伦次。也就是说,ERNIE 3.0需要进行可控学习。
通过将模型预测出的文本属性和原始文本进行拼接,构造从指定属性生成对应文本的预训练数据,模型通过对该数据的学习,实现不同类型的零样本生成能力。用户可以将指定的体裁、情感、长度、主题、关键词等属性自由组合,无需标注任何样本,便可生成不同类型的文本。
另外,百度还提出了可信学习,让ERNIE 3.0学习到的知识更加可靠。
具体来说,通过自监督的对抗训练,让模型学习区分数据是真实的还是模型伪造的,使得模型对生成结果真实性具备判断能力,从而让模型可以从多个候选中选择最可靠的生成结果。
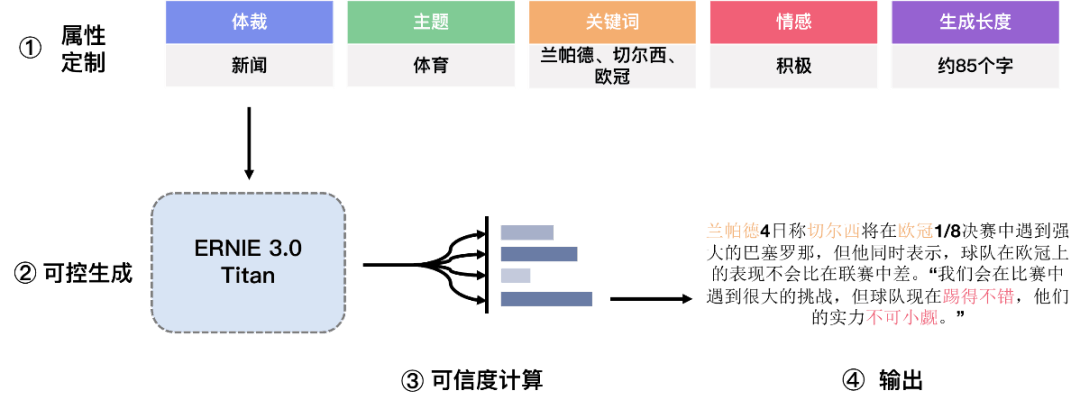
高可信的可控生成预训练
学成出师的ERNIE 3.0,变得更加强大,和庞大——2600亿参数的鹏城-百度·文心。
架构设计上,鹏城-百度·文心采用了双层的语义表示,从而可以同时处理情感分析等语言理解任务,以及机器翻译等语言生成任务。它还能做无标注数据的零样本学习(Zero-shot Learning)和有标注数据的微调训练(Fine-tuning)。
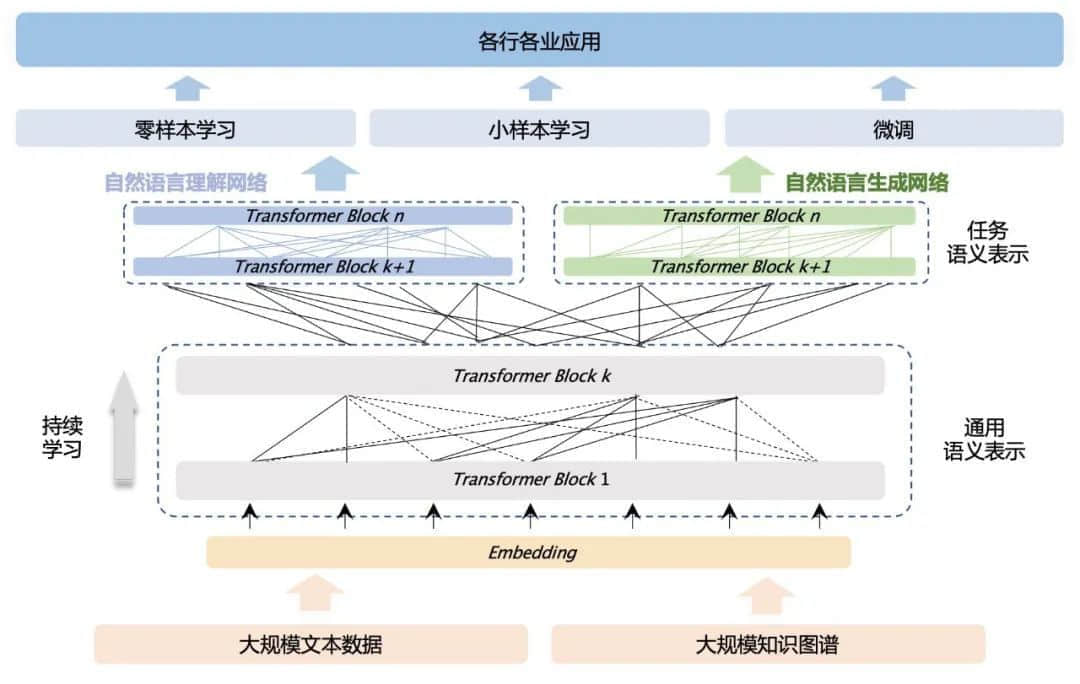
鹏城-百度·文心模型结构图
具备知识内涵的大模型,也就具备了更多对现实的先验洞察,自然在学习新事物时会更加的快,也就是小样本能力更强。
目前,鹏城-百度·文心已在机器阅读理解、文本分类、语义相似度计算等60多项任务中取得最好结果。
在落地场景应用中,模型仅利用少量标注数据甚至无需标注数据,就能解决新场景的任务已成为AI工业大生产的关键。鹏城-百度·文心在30余项小样本和零样本任务上均取得了最优效果。
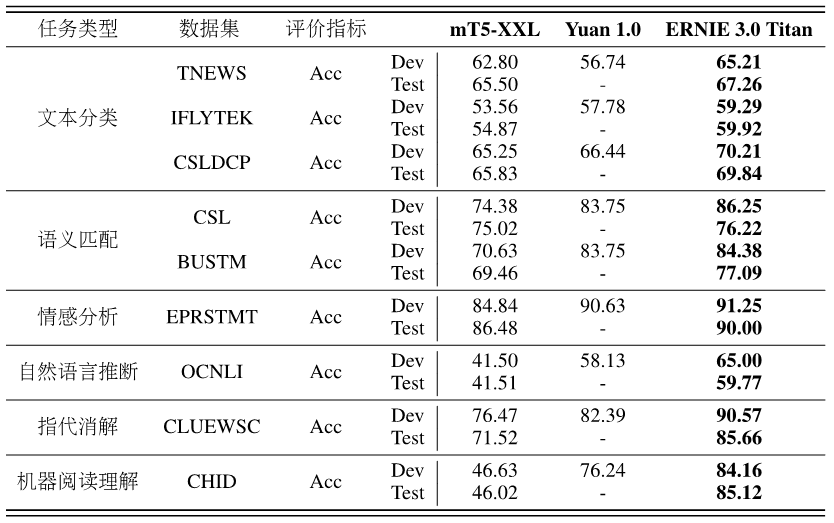
鹏城-百度·文心小样本学习效果
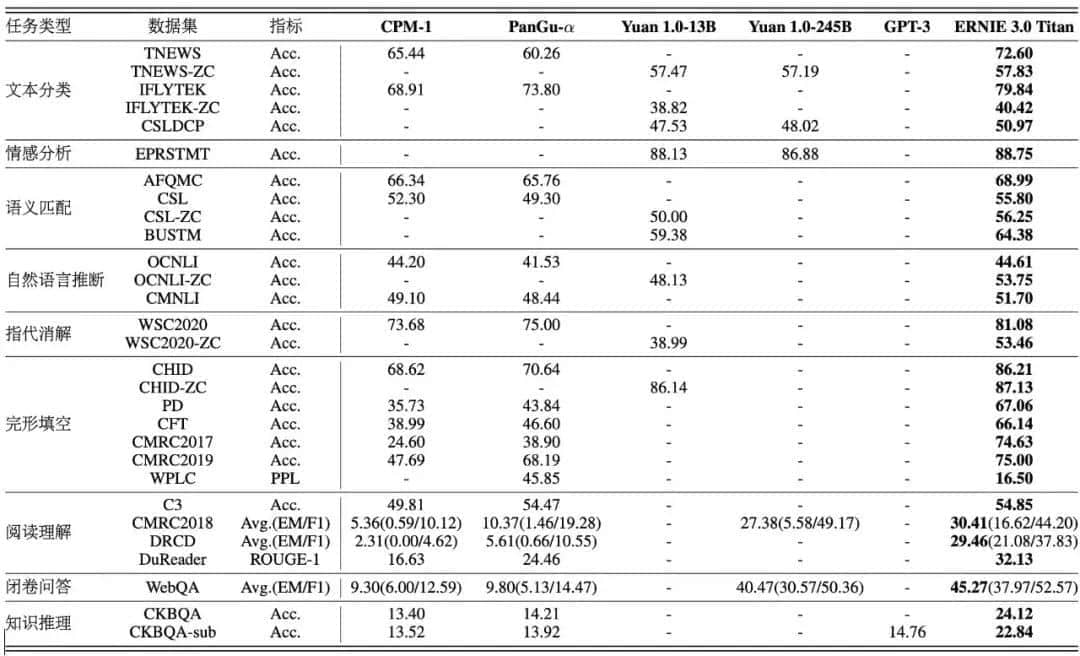
鹏城-百度·文心零样本学习效果
传统的机器学习或深度学习依赖海量的数据,样本量过小容易过拟合,模型表达能力不足。但某些实际场景下样本很难收集,小样本学习致力于在数据资源比较稀少的情况下训练出比较好的模型。
例如在医学领域,部分罕见病例(或新型病例)的数据信息极少。可以利用小样本学习能力的特点,针对性的解决这种病例。
从百亿级到千亿级的跨越,不是简单的线性扩展过程。
正如摩尔定律在发展过程中,随着器件尺寸越来越小,晶体管结构设计变得越来越重要,人们不再简单粗暴地考虑尺寸缩小问题,而是耗费很大的成本去探索晶体管的新型材料、器件结构和工作原理,从而更好地控制其工作电流。
预训练模型也是一样。同时,不同于稀疏专家模型比如 Switch Transformer可以轻易地扩展到万亿参数规模,对于单体模型而言,扩展一个数量级也是非常困难的大工程。
一方面是并行策略。百亿大模型的训练一般用单台V100就可以实现,采用数据并行可以进一步加速。但是,千亿大模型是无法用单机负载的,比如对于2600亿参数的鹏城-百度·文心,一般至少需要32台V100才能负载,而这需要分布式训练的算法来合理编排部署训练模型。
而且,还需要混合使用多种分布式的并行策略,比如层内Tensor并行、层间流水线并行、数据并行、Shard数据并行、优化器并行,同时叠加offload策略、重计算策略。这要求深度学习框架能够支持这些策略的灵活配置,保证收敛性的同时,让用户方便地使用这些算法。Paddle之前也曾就此提出4D训练的概念,也就是混合并行的四个常见维度——层内、层间、数据、优化器。
另外一方面是收敛算法。模型越大,训练成本越高,进而对模型的收敛效率的要求越高。比如鹏城-百度·文心在训练过程中,就需要通过学习率预热策略、渐进式学习策略以及优化的大批量(batch)优化策略,来实现模型的高效收敛,进而保证最终训练效果。
而且,长时间的大规模训练对集群稳定性和调度也是一个考验。机器都是有出错概率的,集群越大出错的概率也就越大。而目前单体模型一般采用的高性能训练模式中,只要单台机器出错就会影响整体过程,底层带来的不稳定性会对训练的进度和运维带来直接的影响。Paddle和集群调度结合可以在训练过程中屏蔽掉出错的机器,减少因而造成的重新调度的时间损耗。
总之,训练一个千亿的大模型是对框架、算法、集群调度的全流程的一个考验。
深度学习本身是一个工程性质很强的学科,而大模型训练的第一步也正是:选择正确的基础设施。
因此,为了实现这次升级,百度在基础设施上下了大功夫,而基础设施的核心是算力以及训练框架。
首先,在算力方面,鹏城-百度·文心模型基于百度百舸集群初始化,然后采用“鹏城云脑II”高性能集群训练。
“鹏城云脑II”是由鹏城实验室联合国内优势科研力量研发的我国首个国产自主E级AI算力平台。在国际超算排行榜上,“鹏城云脑II”实力超群,曾两夺IO 500总榜和10节点榜双料冠军,并在权威AI基准测试MLPerf和AIPerf也收获颇丰,获得多次榜单冠军。
这些成绩充分展现了“鹏城云脑II”优越的智能计算性能和软硬件系统协同水平,也为鹏城-百度·文心大模型强大技术能力奠定基础。
其次,在训练框架方面,鹏城-百度·文心面临着适配性问题。
超大规模模型的训练和推理给深度学习框架带来很大考验,需要利用大规模集群分布式计算才能在可接受时间内完成训练或推理的计算要求,同时面临着模型参数量单机无法加载、多机通信负载重、并行效率低等难题。
早在今年四月,国产深度学习框架百度飞桨就发布了4D混合并行技术,可支持千亿参数规模语言模型的高效分布式训练。但鹏城-百度·文心的训练任务对深度学习框架带来了全新的挑战。
分布式训练的基本步骤有四个:分配所需资源;对 NN 模型进行分区;将每个分区分配给指定的设备;以特定顺序独立执行任务并进行必要的通信;并监控资源状态,调整训练流程。
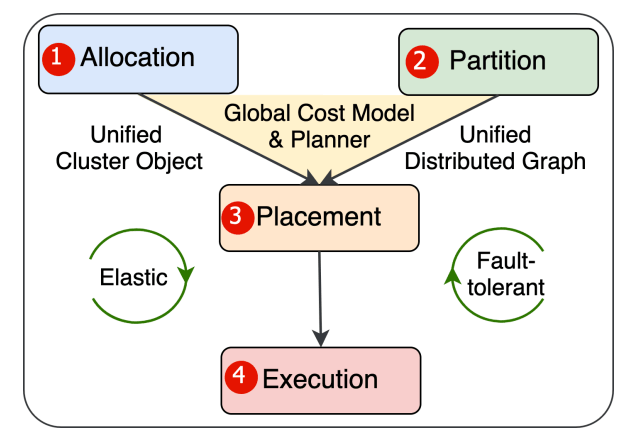
分布式训练的基本步骤
相关阅读 >>
因项目被人接手,百度一96年员工对领导心生不满,故意删改数据库被判刑
chatgpt有何机会和挑战?5g向何处去?百度中兴等高层这样看
李彦宏也谈了新思考:马化腾谈的问题百度都有,我们有很多课要补
更多相关阅读请进入《百度》频道 >>




